本文对Numpy相关的基本概念和常用方法做了一个总结,希望可以帮到需要的人。
Python科学计算工具之——Numpy
![]()
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
应用
- 数据分析
- 机器学习
- 深度学习
为什么使用Numpy
-
运算速度快
-
Python慢
简单来说,因为 Python 执行你代码的时候会执行很多复杂的 “check” 功能,比如当你赋值:
1
b=1; a=b/0.5
这个运算看似简单,但是在计算机内部,b 首先要从一个整数
integer转换成浮点数float,才能进行后面的b/0.5, 因为得到的要是一个小数。 -
Numpy快
-
采用C语言编写
-
向量化运算
a) 使用python的list进行循环遍历运算,
标量化运算:
1 2 3 4 5 6 7 8 9 10
def pySum(): a = list(range(10000)) b = list(range(10000)) c = [] for i in range(len(a)): c.append(a[i]**2 + b[i]**2) return c %timeit pySum() 10 loops, best of 3: 49.4 ms per loop
b) 使用numpy进行
向量化运算:1 2 3 4 5 6 7 8 9
import numpy as np def npSum(): a = np.arange(10000) b = np.arange(10000) c = a**2 + b**2 return c %timeit npSum() The slowest run took 262.56 times longer than the fastest. This could mean that an intermediate result is being cached. 1000 loops, best of 3: 128 µs per loop
从上面的运行结果可以看出,numpy的
向量化运算的效率要远远高于python的循环遍历运算(效率相差好几百倍)。 (1ms=1000µs) -
-
-
资源消耗少
其实 Numpy 就是 C 的逻辑, 创建存储容器 “Array” 的时候是寻找内存上的一连串区域来存放, 而 Python 存放的时候则是不连续的区域, 这使得 Python 在索引这个容器里的数据时不是那么有效率。
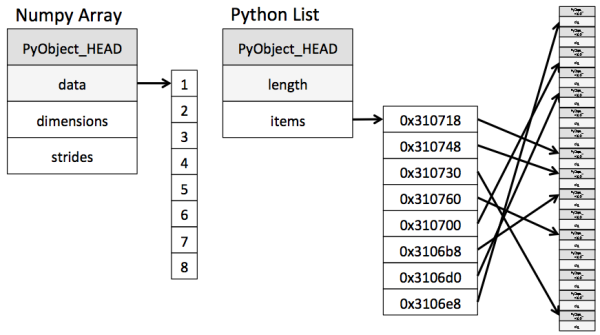
Numpy 快速的矩阵相乘运算, 能将乘法运算分配到计算机中的多个核, 让运算并行。
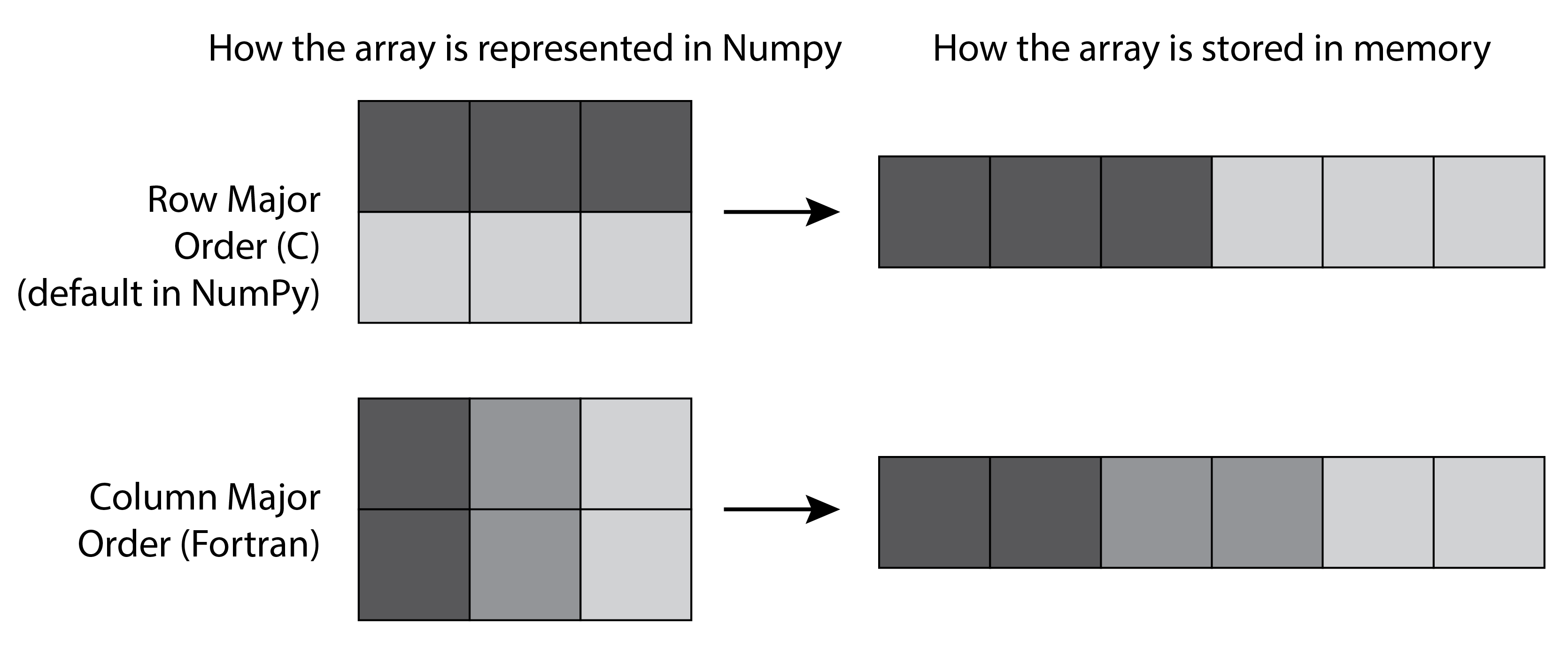
在 Numpy 中, 创建 2D Array 的默认方式是 “C-type” 以 row 为主在内存中排列, 而如果是 “Fortran” 的方式创建的, 就是以 column 为主在内存中排列.
1
2
col_major = np.zeros((10,10), order='C') # C-type
row_major = np.zeros((10,10), order='F') # Fortran
安装
1
2
pip3 install numpy
pip3 install pandas
Numpy 属性
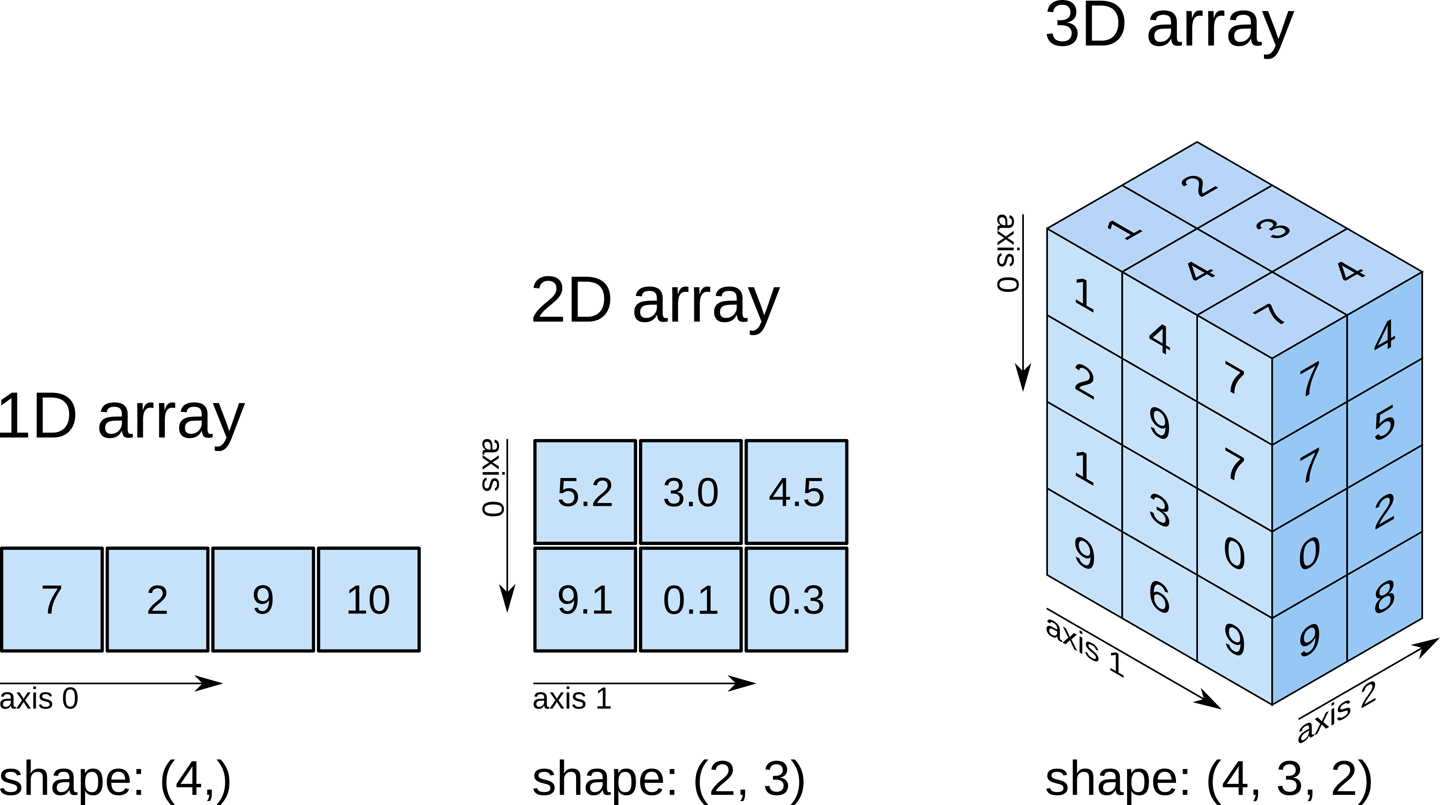
基本属性:
- ndim:维度
- shape:尺寸(行数、列数、深度)
- size:个数
- Itemsize:元素占用大小
- nbytes:总共占用大小
- dtype:数据类型
1
2
3
4
5
6
7
import numpy as np #为了方便使用numpy 采用np简写
array = np.array([[1,2,3],[2,3,4]]) #列表转化为矩阵
print(array)
"""
array([[1, 2, 3],
[2, 3, 4]])
"""
属性结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
print('number of dim:',array.ndim) # 维度
# number of dim: 2
print('shape :',array.shape) # 行数和列数
# shape : (2, 3)
print('size:',array.size) # 元素个数
# size: 6
print('itemsize:',array.itemsize) # 元素大小
# itemsize: 8
print('nbytes:',array.nbytes) # 总大小
# nbytes: 48
print('dtype:',array.dtype) # 元素类型
# dtype: int(64)
创建array
关键字
-
array:创建数组
1 2 3 4 5
a = np.array([2,23,4]) # list 1d,param is list print(a) # [2 23 4] a = np.array((1,2,3)) # list 1d, param is tupple # [1 2 3]
请注意:
- 一维数组用print输出的时候为 [1 2 3 4],跟python的列表是有些差异的,没有“,”
- 在创建二维数组时,在每个子list外面还有一个”[]”,形式为“[[list1], [list2]]”
-
dtype:指定数据类型
1 2 3 4 5 6 7 8 9 10 11 12
a = np.array([2,23,4],dtype=np.int) print(a.dtype) # int 64 a = np.array([2,23,4],dtype=np.int32) print(a.dtype) # int32 a = np.array([2,23,4],dtype=np.float) print(a.dtype) # float64 a = np.array([2,23,4],dtype=np.float32) print(a.dtype) # float32
-
zeros:创建数据全为0
1 2 3 4 5 6
a = np.zeros((3,4)) # 数据全为0,3行4列 """ array([[ 0., 0., 0., 0.], [ 0., 0., 0., 0.], [ 0., 0., 0., 0.]]) """
-
ones:创建数据全为1
1 2 3 4 5 6
a = np.ones((3,4),dtype = np.int) # 数据为1,3行4列 """ array([[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]) """
-
empty:创建数据接近0
1 2 3 4 5 6 7 8 9
a = np.empty((3,4)) # 数据为empty,3行4列 """ array([[ 0.00000000e+000, 4.94065646e-324, 9.88131292e-324, 1.48219694e-323], [ 1.97626258e-323, 2.47032823e-323, 2.96439388e-323, 3.45845952e-323], [ 3.95252517e-323, 4.44659081e-323, 4.94065646e-323, 5.43472210e-323]]) """
-
arrange:按指定范围创建数据
1 2 3 4 5 6 7 8 9 10 11 12
a = np.arange(10,20,2) # 10-19 的数据,2步长 """ array([10, 12, 14, 16, 18]) """ # 使用 reshape 改变数据的形状 a = np.arange(12).reshape((3,4)) # 3行4列,0到11 """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) """
-
linespace:创建线段
1 2 3 4 5 6 7 8
a = np.linspace(1,10,20) # 开始端1,结束端10,且分割成20个数据,生成线段 """ array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684, 3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789, 5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895, 8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ]) """
Numpy 基础运算1
测试数据准备
1
2
3
import numpy as np
a=np.array([10,20,30,40]) # array([10, 20, 30, 40])
b=np.arange(4) # array([0, 1, 2, 3])
几种基本运算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 各位相减
c=a-b # array([10, 19, 28, 37])
# 各位相加
c=a+b # array([10, 21, 32, 43])
# 各位相乘
c=a*b # array([ 0, 20, 60, 120])
# 求幂次方
c=b**2 # array([0, 1, 4, 9])
# sin函数
c=10*np.sin(a)
# array([-5.44021111, 9.12945251, -9.88031624, 7.4511316 ])
# 逻辑判断
print(b<3)
# array([ True, True, True, False], dtype=bool)
# shape mismatch
>>> a = np.arange(4)
>>> a + np.array([1, 2])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: operands could not be broadcast together with shapes (4) (2)
注:都是元素级别,a*b并不是矩阵乘法
多维计算
1
2
3
4
5
6
7
8
9
10
a=np.array([[1,1],[0,1]])
b=np.arange(4).reshape((2,2))
print(a)
# array([[1, 1],
# [0, 1]])
print(b)
# array([[0, 1],
# [2, 3]])
Numpy中的矩阵乘法分为两种, 其一是前文中的对应元素相乘,其二是标准的矩阵乘法运算,即对应行乘对应列得到相应元素:
1
2
3
4
5
6
7
8
9
10
c_dot = np.dot(a,b)
# array([[2, 4],
# [2, 3]])
# or
c_dot_2 = a.dot(b)
# array([[2, 4],
# [2, 3]])
高纬度
1
2
3
4
5
6
7
8
9
10
11
>>> x = np.random.rand(2, 2, 2)
array([[[0.7361712 , 0.66032237],
[0.12326569, 0.00919288]],
[[0.96581673, 0.81417324],
[0.99740315, 0.6730559 ]]])
>>> x.sum(axis=2)[0, 1]
0.13245857180806897
>>> x[0, 1, :].sum()
0.13245857180806897
比较计算
1
2
3
4
5
6
7
8
>>> a = np.array([1, 2, 3, 4])
>>> b = np.array([4, 2, 2, 4])
>>> c = np.array([1, 2, 3, 4])
>>> np.array_equal(a, b)
False
>>> np.array_equal(a, c)
True
Logical计算
1
2
3
4
5
6
>>> a = np.array([1, 1, 0, 0], dtype=bool)
>>> b = np.array([1, 0, 1, 0], dtype=bool)
>>> np.logical_or(a, b)
array([ True, True, True, False], dtype=bool)
>>> np.logical_and(a, b)
array([ True, False, False, False], dtype=bool)
Transcendental计算
1
2
3
4
5
6
7
8
>>> a = np.arange(5)
>>> np.sin(a)
array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 ])
>>> np.log(a)
array([ -inf, 0. , 0.69314718, 1.09861229, 1.38629436])
>>> np.exp(a)
array([ 1. , 2.71828183, 7.3890561 , 20.08553692, 54.59815003])
统计相关
1
2
3
4
5
6
7
8
9
import numpy as np
a=np.random.random((2,4))
print(a)
# array([[ 0.94692159, 0.20821798, 0.35339414, 0.2805278 ],
# [ 0.04836775, 0.04023552, 0.44091941, 0.21665268]])
np.sum(a) # 4.4043622002745959
np.min(a) # 0.23651223533671784
np.max(a) # 0.90438450240606416
如果你需要对行或者列进行查找运算,就需要在上述代码中为 axis 进行赋值。 当axis的值为0的时候,将会以列作为查找单元, 当axis的值为1的时候,将会以行作为查找单元。
1
2
3
4
5
6
7
8
9
10
11
12
print("a =",a)
# a = [[ 0.23651224 0.41900661 0.84869417 0.46456022]
# [ 0.60771087 0.9043845 0.36603285 0.55746074]]
print("sum =",np.sum(a,axis=1)) # equals a.sum(axis=1)
# sum = [ 1.96877324 2.43558896]
print("min =",np.min(a,axis=0))
# min = [ 0.23651224 0.41900661 0.36603285 0.46456022]
print("max =",np.max(a,axis=1))
# max = [ 0.84869417 0.9043845 ]
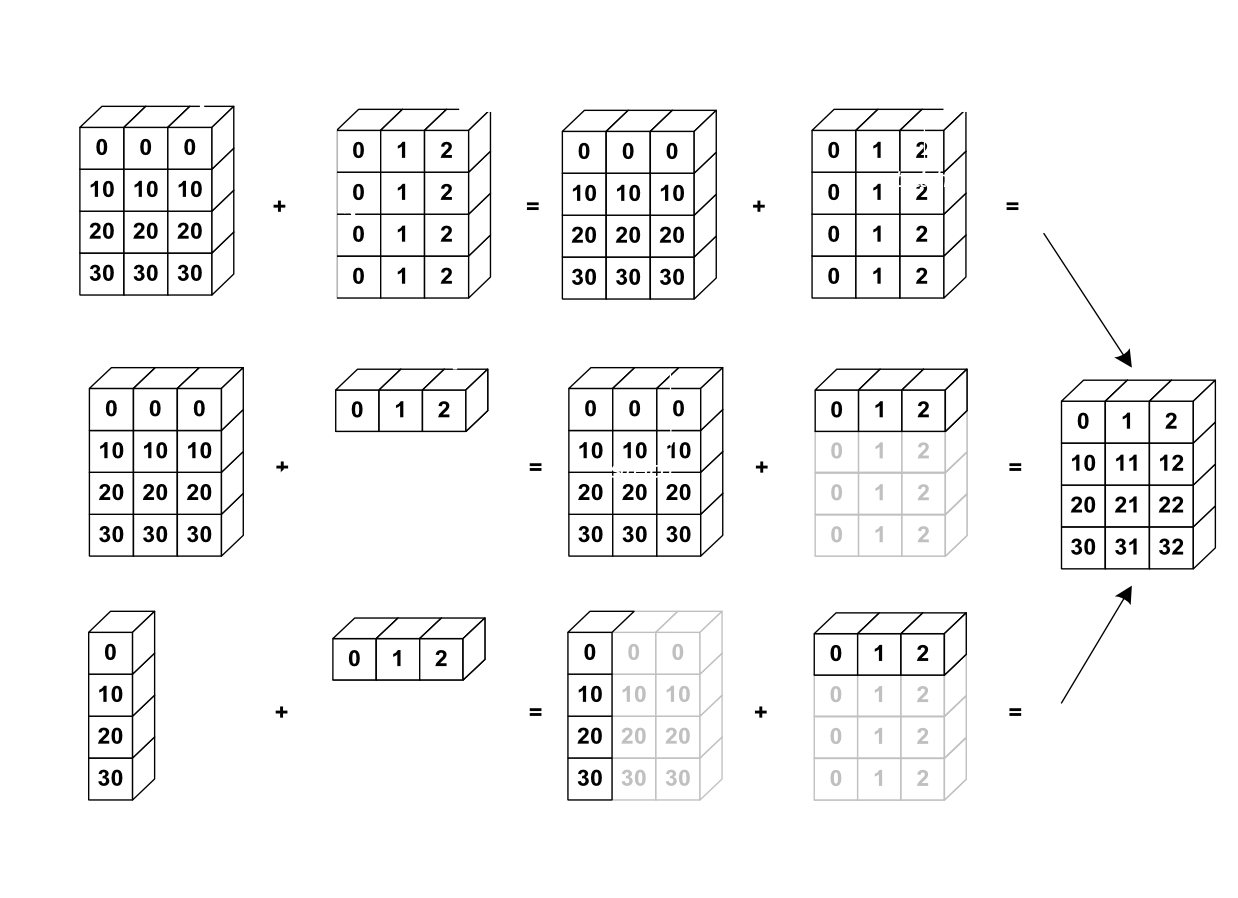
Broadcasting
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
>>> a = np.ones((4, 5))
>>> a[0] = 2 # we assign an array of dimension 0 to an array of dimension 1
>>> a
array([[ 2., 2., 2., 2., 2.],
[ 1., 1., 1., 1., 1.],
[ 1., 1., 1., 1., 1.],
[ 1., 1., 1., 1., 1.]])
>>> a = np.tile(np.arange(0, 40, 10), (3, 1)).T
>>> a
array([[ 0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]])
>>> b = np.array([0, 1, 2])
>>> a + b
array([[ 0, 1, 2],
[10, 11, 12],
[20, 21, 22],
[30, 31, 32]])
Numpy 基础运算2
索引
1
2
3
4
5
6
7
8
9
import numpy as np
A = np.arange(2,14).reshape((3,4))
# array([[ 2, 3, 4, 5]
# [ 6, 7, 8, 9]
# [10,11,12,13]])
print(np.argmin(A)) # 0
print(np.argmax(A)) # 11
统计相关
1
2
3
4
5
6
7
8
9
10
11
12
13
print(np.mean(A)) # 7.5
print(np.average(A)) # 7.5
print(A.mean()) # 7.5
print(A.median()) # 7.5
print(np.cumsum(A))
# [2 5 9 14 20 27 35 44 54 65 77 90]
print(np.diff(A))
# [[1 1 1]
# [1 1 1]
# [1 1 1]]
矩阵转置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import numpy as np
A = np.arange(14,2, -1).reshape((3,4))
print(np.transpose(A))
print(A.T)
# array([[14,10, 6]
# [13, 9, 5]
# [12, 8, 4]
# [11, 7, 3]])
# array([[14,10, 6]
# [13, 9, 5]
# [12, 8, 4]
# [11, 7, 3]])
Numpy 索引
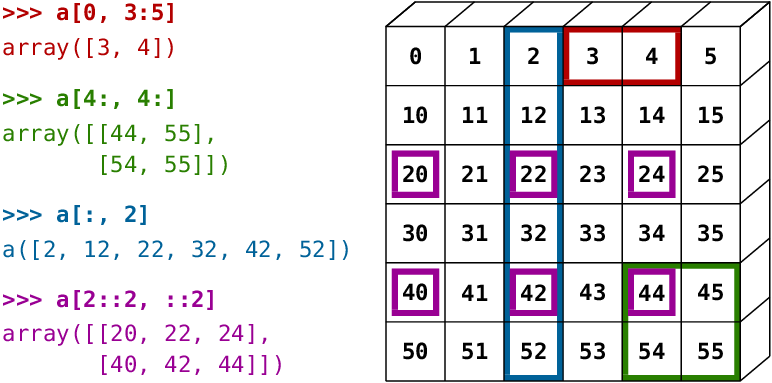
一维索引
- 一维数组
1
2
3
4
5
6
import numpy as np
A = np.arange(3,15)
# array([3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
print(A[3]) # 6
- 二维数组
1
2
3
4
5
6
7
8
9
10
A = np.arange(3,15).reshape((3,4))
"""
array([[ 3, 4, 5, 6]
[ 7, 8, 9, 10]
[11, 12, 13, 14]])
"""
print(A[2])
# [11 12 13 14]
二维索引
1
2
3
4
5
print(A[1][1]) # 8
print(A[1, 1]) # 8
print(A[1, 1:3]) # [8 9]
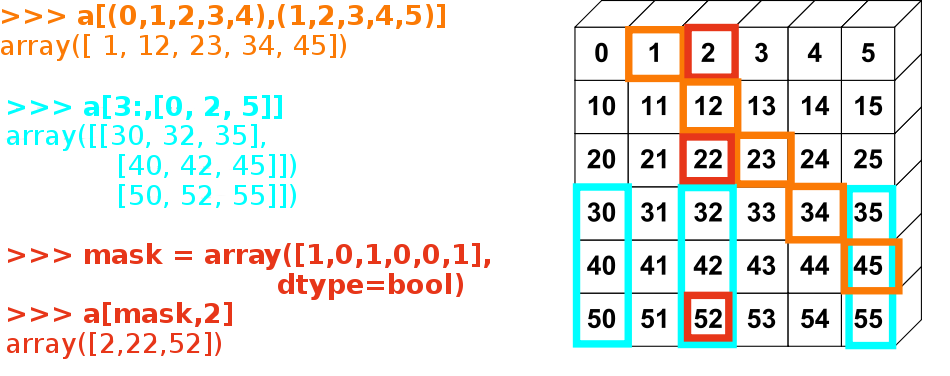
花式索引
逐行打印
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
for row in A:
print(row)
"""
[ 3, 4, 5, 6]
[ 7, 8, 9, 10]
[11, 12, 13, 14]
"""
for column in A.T:
print(column)
"""
[ 3, 7, 11]
[ 4, 8, 12]
[ 5, 9, 13]
[ 6, 10, 14]
"""
迭代输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import numpy as np
A = np.arange(3,15).reshape((3,4))
print(A.flatten())
# array([3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
for item in A.flat:
print(item)
# 3
# 4
……
# 14
flatten是一个展开性质的函数,将多维的矩阵进行展开成1行的数列flat是一个迭代器,返回一个numpy.flatiter对象
多级索引
1
2
3
4
5
6
7
8
9
10
In [73]: pd.Series(np.random.randn(6), index=[['a','a','a','b','b','b'],[1,2,3,1,2,3]])
Out[73]:
a 1 1.144378
2 -0.481547
3 0.532004
b 1 -0.599840
2 1.095235
3 1.260771
dtype: float64
Numpy array合并
np.vstack(tup)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import numpy as np
A = np.array([1,1,1])
B = np.array([2,2,2])
print(np.vstack((A,B))) # vertical stack
"""
[[1,1,1]
[2,2,2]]
"""
C = np.vstack((A,B))
print(A.shape,C.shape)
# (3,) (2,3)
# equals np.concatenate(tup, axis=0)
A仅仅是一个拥有3项元素的数组(数列),而合并后得到的C是一个2行3列的矩阵。
1
2
3
4
5
6
7
8
9
10
>>> a = np.array([[1], [2], [3]])
>>> b = np.array([[2], [3], [4]])
>>> np.vstack((a,b))
array([[1],
[2],
[3],
[2],
[3],
[4]])
np.hstack(tup)
1
2
3
4
5
6
7
8
9
10
D = np.hstack((A,B)) # horizontal stack
print(D)
# [1,1,1,2,2,2]
print(A.shape,D.shape)
# (3,) (6,)
# equals np.concatenate(tup, axis=1)
D本身来源于A,B两个数列的左右合并,而且新生成的D本身也是一个含有6项元素的序列。
1
2
3
4
5
6
7
8
9
10
11
>>> a = np.array((1,2,3))
>>> b = np.array((2,3,4))
>>> np.hstack((a,b))
array([1, 2, 3, 2, 3, 4])
>>> a = np.array([[1],[2],[3]])
>>> b = np.array([[2],[3],[4]])
>>> np.hstack((a,b))
array([[1, 2],
[2, 3],
[3, 4]])
多维数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
>>> ar1 = np.array([[1,2,3], [4,5,6]])
>>> ar2 = np.array([[7,8,9], [11,12,13]])
>>> ar1
array([[1, 2, 3],
[4, 5, 6]])
>>> ar2
array([[ 7, 8, 9],
[11, 12, 13]])
>>> np.concatenate((ar1, ar2)) # 这里的第一轴(axis 0)是行方向
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[11, 12, 13]])
>>> np.concatenate((ar1, ar2),axis=1) # 这里沿第二个轴,即列方向进行拼接
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 11, 12, 13]])
>>> ar3 = np.array([[14,15,16]]) # shape为(1,3)的2维数组
>>> np.concatenate((ar1, ar3)) # 一般进行concatenate操作的array的shape需要一致,当然如果array在拼接axis方向的size不一样,也可以完成
>>> np.concatenate((ar1, ar3)) # ar3虽然在axis0方向的长度不一致,但axis1方向上一致,所以沿axis0可以拼接
array([[ 1, 2, 3],
[ 4, 5, 6],
[14, 15, 16]])
>>> np.concatenate((ar1, ar3), axis=1) # ar3和ar1在axis0方向的长度不一致,所以报错
np.dstack(tup)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
>>> a = np.array((1,2,3))
>>> b = np.array((2,3,4))
>>> np.dstack((a,b)) # shape=(1,3,2)
array([[[1, 2],
[2, 3],
[3, 4]]])
>>>
>>> a = np.array([[1],[2],[3]])
>>> b = np.array([[2],[3],[4]])
>>> np.dstack((a,b)) # shape=(3,1,2)
array([[[1, 2]],
[[2, 3]],
[[3, 4]]])
# equals np.concatenate(tup, axis=2)
关于维度增加的一种理解方式

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
>>> np.hstack((ar1,ar2)) # 水平拼接,沿着行的方向,对列进行拼接, np.column_stack(tup)
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 11, 12, 13]])
>>> np.vstack((ar1,ar2)) # 垂直拼接,沿着列的方向,对行进行拼接,np.row_stack(tup)
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[11, 12, 13]])
>>> np.dstack((ar1,ar2)) # 对于2维数组来说,沿着第三轴(深度方向)进行拼接, 效果相当于stack(axis=-1)
array([[[ 1, 7],
[ 2, 8],
[ 3, 9]],
[[ 4, 11],
[ 5, 12],
[ 6, 13]]])
对于两个shape一样的二维array来说:
- 增加行(对行进行拼接)的方法有:
1
2
3
4
5
6
np.concatenate((ar1, ar2),axis=0)
np.append(ar1, ar2, axis=0)
np.vstack((ar1,ar2))
np.row_stack((ar1,ar2))
np.r_[ar1,ar2]
- 增加列(对列进行拼接)的方法有:
1
2
3
4
5
6
np.concatenate((ar1, ar2),axis=1)
np.append(ar1, ar2, axis=1)
np.hstack((ar1,ar2))
np.column_stack((ar1,ar2))
np.c_[ar1,ar2]
Numpy array分割
纵向分割
1
2
3
4
5
6
7
8
9
print(np.split(A, 2, axis=1))
"""
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
"""
axis为1时会按照行的方向进行分割
横向分割
1
2
3
4
print(np.split(A, 3, axis=0))
# [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
axis为0时会按照列的方向进行分割
错误的分割
范例的Array只有4列,只能等量对分,因此输入以上程序代码后Python就会报错。
1
2
3
4
print(np.split(A, 3, axis=1))
# ValueError: array split does not result in an equal division
不等量的分割
1
2
3
4
5
6
7
8
9
10
11
print(np.array_split(A, 3, axis=1))
"""
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2],
[ 6],
[10]]), array([[ 3],
[ 7],
[11]])]
"""
其他分割方式
在Numpy里还有np.vsplit()与横np.hsplit()方式可用。
1
2
3
4
5
6
7
8
9
10
11
12
13
print(np.vsplit(A, 3)) #等于 print(np.split(A, 3, axis=0))
# [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
print(np.hsplit(A, 2)) #等于 print(np.split(A, 2, axis=1))
"""
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
"""
- vsplit可以理解为在垂直方向进行切分,并不是垂直去切水平方向的数据
- hsplit可以理解为在水平方向进行切分,并不是水平去切垂直方向的数据
Numpy copy & deep copy
注意=号具有关联性,需要使用np.copy()来进行深度拷贝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
>>> a = np.arange(10)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = a[::2]
>>> b
array([0, 2, 4, 6, 8])
>>> np.may_share_memory(a, b)
True
>>> b[0] = 12
>>> b
array([12, 2, 4, 6, 8])
>>> a # (!)
array([12, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> a = np.arange(10)
>>> c = a[::2].copy() # force a copy
>>> c[0] = 12
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.may_share_memory(a, c)
False
copy慢view快
1
2
3
4
5
6
7
8
9
10
11
12
13
14
a = np.zeros((1000, 1000))
b = np.zeros((1000, 1000))
N = 9999
def f1(a):
for _ in range(N):
a *= 2 # same as a[:] *= 2
def f2(b):
for _ in range(N):
b = 2*b
print('%f' % ((t1-t0)/N)) # f1: 0.000837
print('%f' % ((t2-t1)/N)) # f2: 0.001346
Resources
-
https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/
-
https://morvanzhou.github.io/tutorials/data-manipulation/np-pd/4-1-speed-up-numpy/
-
http://gouthamanbalaraman.com/blog/numpy-vs-pandas-comparison.html
本文首次发布于 LiuShuo’s Blog, 转载请保留原文链接.