Spliterator是一个可分割迭代器(Splittable Iterator),JDK8发布后,对于并行处理的能力大大增强,Spliterator就是为了并行遍历&分割序列而设计的一个迭代器。本文对其进行分析。
并行计算
在Java7中引入了ForkJoinPool框架使得并行计算变得非常方便,它可以利用多核加速计算,同时不必手工实现复杂的多线程程序,底层直接帮我们实现好。
对于Stream来说,并行流同样是一种快速计算集合数据的方式,它的底层就是依赖ForkJoinPool来实现的。
默认Collection接口实现了parallelStream()
1
2
3
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
并行流底层调用StreamSupport的工具方法stream(Spliterator s, boolean parallel),其中Collection也提供了默认的spliterator方下:
1
2
3
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
对于子类集合来说应尽量覆盖这个方法以更高效的方式来分割迭代本集合中的数据序列:
The default implementation should be overridden by subclasses that can return a more efficient spliterator.
比如对于ArrayList来说,它实现了自己的分割迭代器ArrayListSpliterator:
1
2
3
4
// Creates a late-binding and fail-fast Spliterator over the elements in this list.
public Spliterator<E> spliterator() {
return new ArrayListSpliterator<>(this, 0, -1, 0); // 将当前List实例传进去,origin=0,expectModCount=0
}
它有两个特点:
Late-BindingA late-binding Spliterator binds to the source of elements at the point of first traversal, first split, or first query for estimated size, rather than at the time the Spliterator is created. A Spliterator that is not late-binding binds to the source of elements at the point of construction or first invocation of any method. Modifications made to the source prior to binding are reflected when the Spliterator is traversed.Fail-FastAfter binding a Spliterator should, on a best-effort basis, throw ConcurrentModificationException if structural interference is detected. Spliterators that do this are called fail-fast.
求最大值
1
2
int max = numbers.parallelStream().reduce(0, Integer::max, Integer::max);
System.out.println("Parallel: " + max);
调用并行流的调用栈如下:
parallelStream()
StreamSupport.stream(spliterator(), true) ArrayList.spliterator() ArrayListSpliterator<>()
由Spliterator来实现分割逻辑,一直到无法继续分割,再对子结果集进行合并。
Spliterator
JDK8中引入的新接口,可以实现对元素序列的遍历和分割,它可以实现并行流计算:
1
2
3
4
5
6
7
8
public interface Spliterator<T> {
boolean tryAdvance(Consumer<T> action);
default void forEachRemaining(Consumer<T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}
对接口的介绍使用一篇英文博客,摘自这里 ,这是我找到的最容易理解的解释,比很多中文冗长又不全面的理解强很多:
- tryAdvance method is used to consume an element of the spliterator. This method returns either true indicating still more elements exist for processing otherwise false to signify all the elements of the spliterator is processed and can be exited.
- forEachRemaining is a default method available in Spliterator interface that indicates the spliterator to take certain action when no more splitting require. Basically this performs the given action for each remaining element, sequentially in the current thread, until all elements have been processed.
1 2 3 4 5
default void forEachRemaining(Consumer<T> action) { do { } while (tryAdvance(action)); }
If you see the forEachRemaining method default implementation, it repeatedly calls the tryAdvance method to process the spliterator elements sequentially. While splitting task when a spliterator finds itself to be small enough that can be executed sequentially then it calls forEachRemaining method on its elements.
-
trySplit is used to partition off some of its elements to second spliterator allowing both of them to process parallelly. The idea behind this splitting is to allow balanced parallel computation on a data structure. These spliterators repeatedly calls trySplit method unless spliterator returns null indiacating end of splitting process.
-
estimateSize returns an estimate of the number of elements available in spliterator. Usually this method is called by some forkjoin tasks like AbstractTask to check size before calling trySplit.
- characteristics method reports a set of characteristics of its structure, source, and elements from among ORDERED, DISTINCT, SORTED, SIZED, NONNULL, IMMUTABLE, CONCURRENT, and SUBSIZED. These helps the Spliterator clients to control, specialize or simplify computation. For example, a Spliterator for a Collection would report SIZED, a Spliterator for a Set would report DISTINCT, and a Spliterator for a SortedSet would also report SORTED.
ArrayListSpliterator
源码
下面我们来看一下ArrayList对Spliterator的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
/**
* 基于索引的、二分的、懒加载器
* Index-based split-by-two, lazily initialized Spliterator
*/
static final class ArrayListSpliterator<E> implements Spliterator<E> {
// 用于存放ArrayList对象
private final ArrayList<E> list;
// 当前位置(包含),advance/spilt操作时会被修改
private int index; // current index, modified on advance/split
// 结束位置(不包含),-1表示到最后一个元素
private int fence; // -1 until used; then one past last index
// 用于存放list的modCount
private int expectedModCount; // initialized when fence set
/**
* Create new spliterator covering the given range
*/
ArrayListSpliterator(ArrayList<E> list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
// 第一次使用时实例化结束位置
private int getFence() { // initialize fence to size on first use
int hi; // (a specialized variant appears in method forEach)
ArrayList<E> lst;
// 第一次初始化时,fence才会小于0
if ((hi = fence) < 0) {
// 如果集合中没有元素
if ((lst = list) == null)
hi = fence = 0;
else {
// 其他场景直接使用fence为list的长度,expectedModCount为list的modCount
expectedModCount = lst.modCount; // 使用list的modCount初始化
hi = fence = lst.size;
}
}
return hi;
}
// 分割list,返回一个新分割出的spilterator实例
// 相当于二分法,这个方法会递归
// 1. ArrayListSpilterator本质还是对原list进行操作,只是通过index和fence来控制每次处理的范围
public ArrayListSpliterator<E> trySplit() {
// hi结束位置(不包括) lo:开始位置 mid中间位置
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
// 当lo >= mid, 表示不能再分割
// 当lo < mid时,表示可以分割,切割(lo, mid)出去,同时更新index = mid
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator<E>(list, lo, index = mid,
expectedModCount);
}
/**
* 返回true时,表示可能还有元素未处理
* 返回false时,表示没有剩余元素处理了
*
* @param action
* @return
*/
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) {
index = i + 1;
@SuppressWarnings("unchecked") E e = (E) list.elementData[i];
action.accept(e);
//遍历时,结构发生变更,抛错
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
/**
* 顺序遍历处理所有剩下的元素
*
* @param action
*/
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst;
Object[] a;
if (action == null)
throw new NullPointerException();
// 如果list不为空,且list中的元素不为空
if ((lst = list) != null && (a = lst.elementData) != null) {
// 当fence < 0 时,表示fence和exceptModCount未初始化
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
} else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
// list为null表示已经被修改,直接抛异常
throw new ConcurrentModificationException();
}
// 估算大小
public long estimateSize() {
return (long) (getFence() - index);
}
// 返回特征值
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
由于实现是基于数组下标的分割来切分Spliterator的,每部分可以交给不同的线程去执行,所以是线程安全的。
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import java.util.ArrayList;
import java.util.Spliterator;
import java.util.function.Consumer;
public class IteratorTest {
public static void main(String[] args) {
ArrayList<String> arrays = new ArrayList<String>();
arrays.add("a");
arrays.add("b");
arrays.add("c");
arrays.add("d");
arrays.add("e");
arrays.add("f");
arrays.add("g");
arrays.add("h");
arrays.add("i");
arrays.add("j");
arrays.remove("j");
Spliterator<String> p = arrays.spliterator();
Spliterator<String> s1 = p.trySplit(); // 先从p中分割一部分
Spliterator<String> s2 = p.trySplit(); // 再将切分后的p再进行一次分割
System.out.println("p.consume :");
p.forEachRemaining(new Consumer<String>() {
public void accept(String s) {
System.out.println(s);
}
});
System.out.println("s1.consume");
s1.forEachRemaining(new Consumer<String>() {
public void accept(String s) {
System.out.println(s);
}
});
System.out.println("s2.consume");
s2.forEachRemaining(new Consumer<String>() {
public void accept(String s) {
System.out.println(s);
}
});
}
}
p刚开是集合默认的Spliterator,然后分别调用了两次trySplit方法,并分别赋值给了s1和s2,根据对源码的分析我们知道,每次进行trySplit
都会对当前的迭代分割器进行二分分割。
输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
p.consume :
g
h
i
s1.consume :
a
b
c
d
s2.consume :
e
f
用Spliterator求最大值
这里的例子同样摘自上述博客,通过Spliterator实现并行计算整数元素序列的最大值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
public class SpliteratorTest {
public static void main(String[] args) {
Random random = new Random(100);
int[] array = IntStream.rangeClosed(1, 1_000_000).map(random::nextInt)
.map(i -> i * i + i).skip(20).toArray();
int max = StreamSupport.stream(new FindMaxSpliterator(array, 0, array.length - 1), true) //注意这里是并行流
.reduce(0, Integer::max, Integer::max);
System.out.println(max);
}
private static class FindMaxSpliterator implements Spliterator<Integer> {
int start, end;
int[] arr;
public FindMaxSpliterator(int[] arr, int start, int end) {
this.arr = arr;
this.start = start;
this.end = end;
}
@Override
public boolean tryAdvance(Consumer<? super Integer> action) {
if (start <= end) {
action.accept(arr[start]);
start++;
return true;
}
return false;
}
@Override
public Spliterator<Integer> trySplit() {
if (end - start < 1000) { // 小于1000则不再切分
return null;
}
int mid = start + (end - start)/2; // 分两半
int oldstart = start;
start = mid + 1; // 重新修改了start,当前Spliterator只处理[mid+1, end]的部分
return new FindMaxSpliterator(arr, oldstart, mid); // 分割出去前半部分,可以用于并行处理
}
@Override
public long estimateSize() {
return end - start;
}
@Override
public int characteristics() { // 注意这里的IMMUTABLE
return ORDERED | SIZED | IMMUTABLE | SUBSIZED;
}
// 注意没有覆盖forEachRemaining()方法,使用默认的实现,即串行消费所有剩余元素
}
}
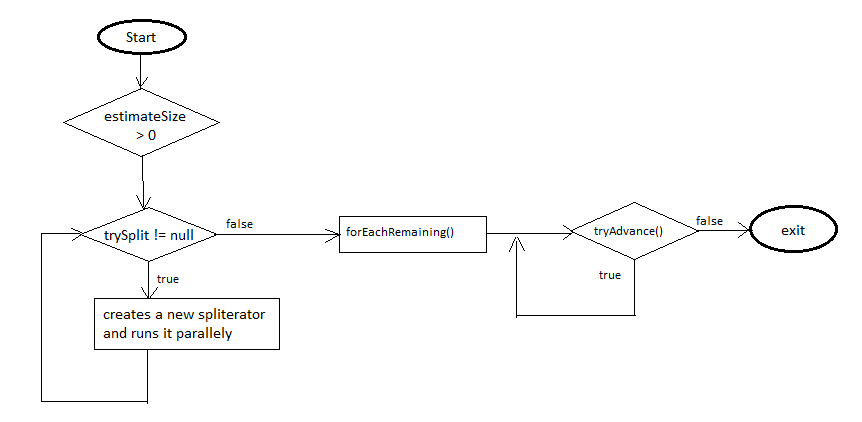
它的工作原理可以用下面的这张图来描述:
注意
Parallel Stream使用了ForkJoinPool和Spliterator
的特性实现了并行计算,但是需要注意使用它的场景:只适用集合数据量大的场景,比如只有几千个元素的场景使用并行流的方式计算将小高更多的资源,因为分割和合并会消耗很大的资源,而串行计算则不需要。
Spliterator.OfPrimitive
OfPrimitive 接口定义了原始数据的分割迭代器,注意接口参数的声明 T_SPLITR 本质上还是 OfPrimitive , 通过 trySplit
方法的返回值可知,分割后的可分割迭代器必须和之前的类型相同:
1
2
3
4
5
6
7
8
9
10
11
12
public interface OfPrimitive<T, T_CONS, T_SPLITR extends Spliterator.OfPrimitive<T, T_CONS, T_SPLITR>>
extends Spliterator<T> {
@Override
T_SPLITR trySplit();
boolean tryAdvance(T_CONS action);
default void forEachRemaining(T_CONS action) {
do { } while (tryAdvance(action));
}
}
Spliterator.IntOf
来看一下 IntOf 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
public interface OfInt extends OfPrimitive<Integer, IntConsumer, OfInt> {
@Override
OfInt trySplit();
@Override
boolean tryAdvance(IntConsumer action);
@Override
default void forEachRemaining(IntConsumer action) {
do { } while (tryAdvance(action));
}
/**
* {@inheritDoc}
* @implSpec
* If the action is an instance of {@code IntConsumer} then it is cast
* to {@code IntConsumer} and passed to
* {@link #tryAdvance(java.util.function.IntConsumer)}; otherwise
* the action is adapted to an instance of {@code IntConsumer}, by
* boxing the argument of {@code IntConsumer}, and then passed to
* {@link #tryAdvance(java.util.function.IntConsumer)}.
*/
@Override
default boolean tryAdvance(Consumer<? super Integer> action) {
if (action instanceof IntConsumer) {
return tryAdvance((IntConsumer) action);
}
else {
if (Tripwire.ENABLED)
Tripwire.trip(getClass(),
"{0} calling Spliterator.OfInt.tryAdvance((IntConsumer) action::accept)");
return tryAdvance((IntConsumer) action::accept);
}
}
/**
* {@inheritDoc}
* @implSpec
* If the action is an instance of {@code IntConsumer} then it is cast
* to {@code IntConsumer} and passed to
* {@link #forEachRemaining(java.util.function.IntConsumer)}; otherwise
* the action is adapted to an instance of {@code IntConsumer}, by
* boxing the argument of {@code IntConsumer}, and then passed to
* {@link #forEachRemaining(java.util.function.IntConsumer)}.
*/
@Override
default void forEachRemaining(Consumer<? super Integer> action) {
if (action instanceof IntConsumer) {
forEachRemaining((IntConsumer) action);
}
else {
if (Tripwire.ENABLED)
Tripwire.trip(getClass(),
"{0} calling Spliterator.OfInt.forEachRemaining((IntConsumer) action::accept)");
forEachRemaining((IntConsumer) action::accept);
}
}
}
注意里面的两个 tryAdvance 方法,一个是实现了父接口 OfPrimitive 的:
1
2
@Override
boolean tryAdvance(IntConsumer action);
一个是自己接口的:
1
2
3
4
5
6
7
8
9
10
11
12
@Override
default boolean tryAdvance(Consumer<? super Integer> action) {
if (action instanceof IntConsumer) {
return tryAdvance((IntConsumer) action);
}
else {
if (Tripwire.ENABLED)
Tripwire.trip(getClass(),
"{0} calling Spliterator.OfInt.tryAdvance((IntConsumer) action::accept)");
return tryAdvance((IntConsumer) action::accept);
}
}
它的参数是 Consumer<? super Integer> ,如果它是 IntConsumer 实例的则直接转换为 IntConsumer 进行调用第一个
tryAdvance 方法;否则将其适配成 IntConsumer 通过将其参数进行封箱操作 boxing 后传递给第一个 tryAdvance 方法。
otherwise the action is adapted to an instance of {@code IntConsumer}, by boxing the argument of
{@code IntConsumer}, and then passed to{@link #tryAdvance(java.util.function.IntConsumer)}
Spliterator.OfInt的实现
在 Spliterators 类中,已经实现了针对 int[] 数据分割迭代器,和 ArrayList 差不多,可以简单的看一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
//与ArrayList不同的是,array是实现声明的,因此不必担心遍历过程中发生结构变更。
static final class IntArraySpliterator implements Spliterator.OfInt {
private final int[] array;
private int index;
private final int fence;
//用于记录特征值
private final int characteristics;
// 初始构造器
public IntArraySpliterator(int[] array, int additionalCharacteristics) {
this(array, 0, array.length, additionalCharacteristics);
}
public IntArraySpliterator(int[] array, int origin, int fence, int additionalCharacteristics) {
this.array = array;
this.index = origin;
this.fence = fence;
this.characteristics = additionalCharacteristics | Spliterator.SIZED | Spliterator.SUBSIZED;
}
@Override
public OfInt trySplit() {
//分割,上面做个介绍,不在赘述
int lo = index, mid = (lo + fence) >>> 1;
return (lo >= mid)
? null
: new IntArraySpliterator(array, lo, index = mid, characteristics);
}
@Override
public void forEachRemaining(IntConsumer action) {
int[] a; int i, hi; // hoist accesses and checks from loop
if (action == null)
throw new NullPointerException();
if ((a = array).length >= (hi = fence) &&
(i = index) >= 0 && i < (index = hi)) {
do { action.accept(a[i]); } while (++i < hi);
}
}
@Override
public boolean tryAdvance(IntConsumer action) {
if (action == null)
throw new NullPointerException();
if (index >= 0 && index < fence) {
action.accept(array[index++]);
return true;
}
return false;
}
@Override
public long estimateSize() { return (long)(fence - index); }
@Override
public int characteristics() {
return characteristics;
}
@Override
public Comparator<? super Integer> getComparator() {
if (hasCharacteristics(Spliterator.SORTED))
return null;
throw new IllegalStateException();
}
}
一个有趣的地方
注意到两个 tryAdvance 的参数不一样,一个是 IntConsumer , 这个方法来自 OfPrimitive 接口,另外一个 tryAdvance 的参数是
Consumer<? super Integer> 它是 Spliterator 接口中的定义。
但后者却可以直接转换为前者方法的参数进行调用,但 Consumer 接口和 IntConsumer 接口是两个没有继承关系的独立接口,只是接口的声明很像。
IntConsumer 接口的定义:
1
2
3
4
5
6
7
8
9
10
11
@FunctionalInterface
public interface IntConsumer {
void accept(int value);
default IntConsumer andThen(IntConsumer after) {
Objects.requireNonNull(after);
return (int t) -> { accept(t); after.accept(t); };
}
}
Consumer 接口的定义:
1
2
3
4
5
6
7
8
9
10
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
什么情况下下面的条件会返回 true 呢?
1
2
3
private static void test(Consumer<? super Integer> consumer) {
System.out.println(consumer instanceof IntConsumer);
}
下面几种方式都会打印出 false ,为什么?
1
2
3
4
5
6
Consumer<Integer> consumer = i -> System.out.println(i);
IntConsumer intConsumer = i -> System.out.println(i);
test(consumer); // 面向对象的方式
test(consumer::accept); // 函数式的方式
test(intConsumer::accept); // 函数式的方式
前两种方式不需要解释,为什么第三种也不行呢?答案在于 test 方法的参数是 Consumer 接口,而它与 IntConsumer 接口没有关系,所以不会返回 true 。
那为什么会赋值成功呢?
因为lambda表达式是通过上下文进行推断的。
intConsumer::accept会被自动推断为是Consumer类型。
那么怎么才能达到我们的目的呢?答案是————同时实现两个接口:
1
2
3
4
5
6
7
8
lass MyConsumer<Integer> implements IntConsumer, Consumer<Integer> {
public void accept(int value) {
System.out.println(value);
}
public void accept(Integer t) {
System.out.println(t);
}
}
所以该实例传递为参数后,既满足 Consumer 类型的入参,又满足内部对 IntConsumer 类型的判断。
References
- https://java8tips.readthedocs.io/en/stable/parallelization.html
- https://java8tips.readthedocs.io/en/stable/forkjoin.html
- https://blog.csdn.net/jiangmingzhi23/article/details/78927552
- https://www.ibm.com/developerworks/cn/java/j-java-streams-5-brian-goetz/index.html
- https://www.ibm.com/developerworks/cn/java/j-java-streams-3-brian-goetz/index.html
- https://www.baeldung.com/java-spliterator
- https://blog.csdn.net/lh513828570/article/details/56673804
- http://movingon.cn/2017/05/03/jdk8-%E4%B8%80%E4%B8%AA%E9%A2%A0%E8%A6%86%E4%BA%86%E9%9D%A2%E5%90%91%E5%AF%B9%E8%B1%A1%E8%AE%A4%E7%9F%A5%E7%9A%84%E4%BE%8B%E5%AD%90/
本文首次发布于 LiuShuo’s Blog, 转载请保留原文链接.