本文从经典的缓存更新策略谈数据的一致性问题并给出解决方案。
常见的更新策略
1. 先更新数据库再删缓存
- 目的:保证此时DB数据最新,由删除后的读操作来load最新数据
- 可能:一个线程在读miss后加载了此时的旧数据,在写线程删除缓存后写了进去
- 结果:缓存还是旧数据
这种并发的概率极低。因为这个条件需要发生在读缓存时缓存失效,而且有一个并发的写操作。实际上数据库的写操作会比读操作慢得多,而且还要加锁,而读操作必需在写操作前进入数据库操作,又要晚于写操作更新缓存,所有这些条件都具备的概率并不大。但是为了避免这种极端情况造成脏数据所产生的影响,我们还是要为缓存设置过期时间。
2. 更新数据后直接更新缓存
- 目的:保证一致性
- 可能:两个线程同时写(并发写),先执行完数据库更新操作的线程被挂起,后执行数据库更新的线程又更新了缓存,然后挂起线程又恢复执行,将旧数据写进缓存
- 结果:缓存还是旧数据
3. 先删除缓存再更新数据库
- 目的:不详(因为这个逻辑是错误的)
- 可能:删除缓存后更新数据库之前已经有读线程加载了旧数据并写到了缓存
- 结果:缓存还是旧数据
总结
可知,在多线程环境下,任何线程的调度以及执行过程中CPU时间片的分配都是不可预知的,所以一些常规的想法可能并不一定按照预期的结果执行。
所以操作数据库和缓存的先后顺序并不是解决问题的思路,因为无论如何排列均可能造成脏数据问题。
读操作不回填缓存
如果将读操作和回填缓存分离开,将回填工作交给独立的模块去执行,将读写并发以及写写并发的结果「串行化」,则可以避免因为并发更新的时序问题带来的缓存数据库不一致的问题。
如可以使用消息队列来串行化数据的更新操作,并由独立的模块去执行缓存的更新操作,只要保证了Key的顺序消费即可以避免缓存数据库不一致的问题。
新问题
因为写数据库和发送消息是独立的,可能数据库更新成功了但是消息发送失败,此时数据库和缓存又出现了不一致。
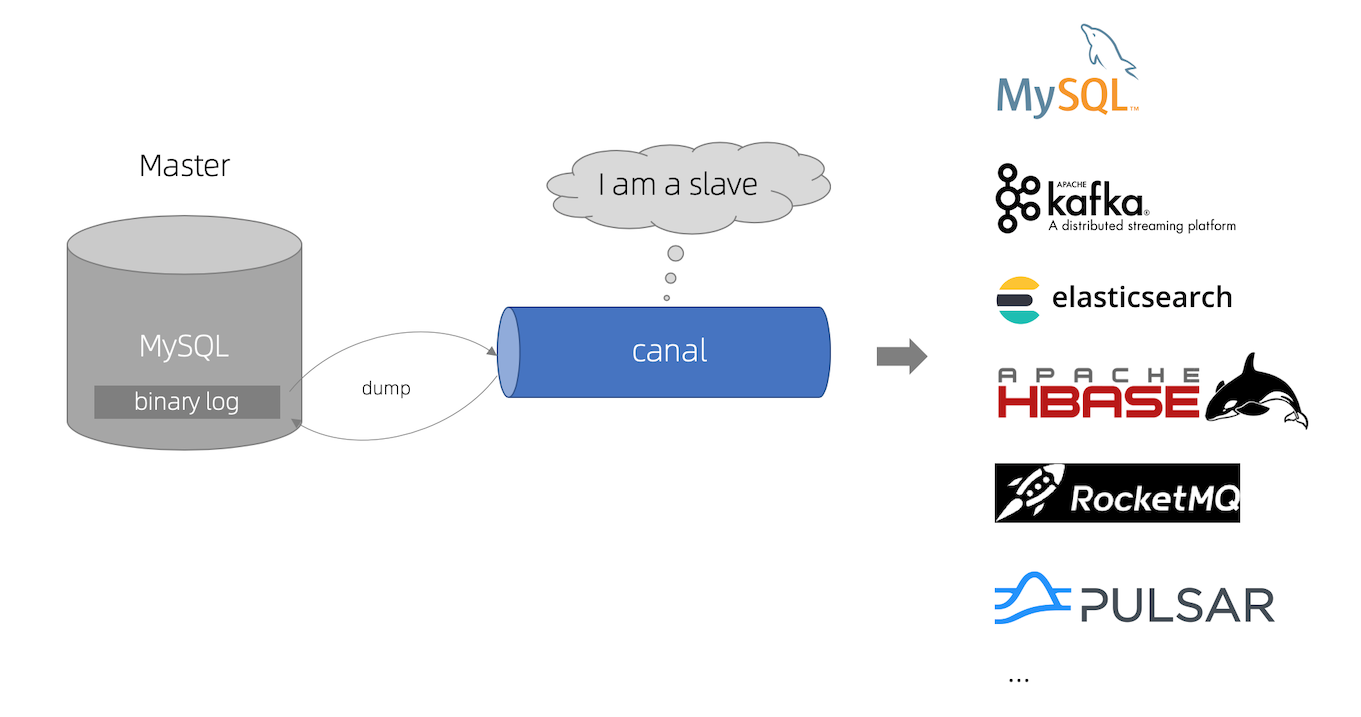
一种思路是消费数据库的binlog数据,binlog的数据由数据库本身保证,只要写库成功一定会写binlog。如使用阿里开源的canal:
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
MySQL主备复制原理
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
References
本文首次发布于 LiuShuo’s Blog, 转载请保留原文链接.