SkipList最早是在1990年由William Pugh提出的,目的是提供一种替换平衡树的可能性,本文对其进行一定的分析。
概念来源
先贴出论文地址: Skip Lists: A Probabilistic Alternative to Balanced Trees , 感兴趣的可以先拜读一下。
由论文标题可知,SkipList的设计初衷是作为替换平衡树的一种选择。我们都知道,AVL树有着严格的O(logN)的查询效率,但是由于插入过程中可能需要多次旋转,导致插入效率较低,因而才有了在工程界更加实用的红黑树。
但是红黑树有一个问题就是在并发环境下使用不方便,比如需要更新数据时,Skip需要更新的部分比较少,锁的东西也更少,而红黑树有个平衡的过程,在这个过程中会涉及到较多的节点,需要锁住更多的节点,从而降低了并发性能。
在Redis和Google的著名项目BigTable中都使用了该数据结构。 下面内容出自Redis 设计与实现:
Redis 使用跳跃表作为有序集合键的底层实现之一: 如果一个有序集合包含的元素数量比较多, 又或者有序集合中元素的成员(member)是比较长的字符串时, Redis 就会使用跳跃表来作为有序集合键的底层实现。
和链表、字典等数据结构被广泛地应用在 Redis 内部不同, Redis 只在两个地方用到了跳跃表, 一个是实现有序集合键, 另一个是在集群节点中用作内部数据结构, 除此之外, 跳跃表在 Redis 里面没有其他用途。
原理
其实跳表就是在普通单向链表的基础上增加了一些索引,而且这些索引是分层的,从而可以快速地查的到数据。下图来源自论文:

注:本文中所有图都源自论文,但引自ict2014的博客,他对论文中的图进行截取并增加了描绘内容,更便于理解。
从图中可以看到, 跳跃表主要由以下部分构成:
- 表头(header):负责维护跳跃表的节点指针。
- 跳跃表节点(node):保存着元素值,以及多个层。
- 层(level):保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
- 表尾(footer):全部由 NULL 组成,表示跳跃表的末尾。
查找

- 从header出发,从高到低的level进行查找,先索引到9这个结点,发现9 < 19,继续查找(然后在level==2这层),查找到21这个节点,由于21 > 19, 所以结点不往前走,而是level由2降低到1
- 然后索引到17这个节点,由于17 < 19, 所以继续往后,索引到21这个结点,发现21>19, 所以level由1降低到0
- 在结点17上,level==0索引到19,查找完毕。
- 如果在level==0这层没有查找到,那么说明不存在key为19的节点,查找失败
插入
如下是插入结点示意图:
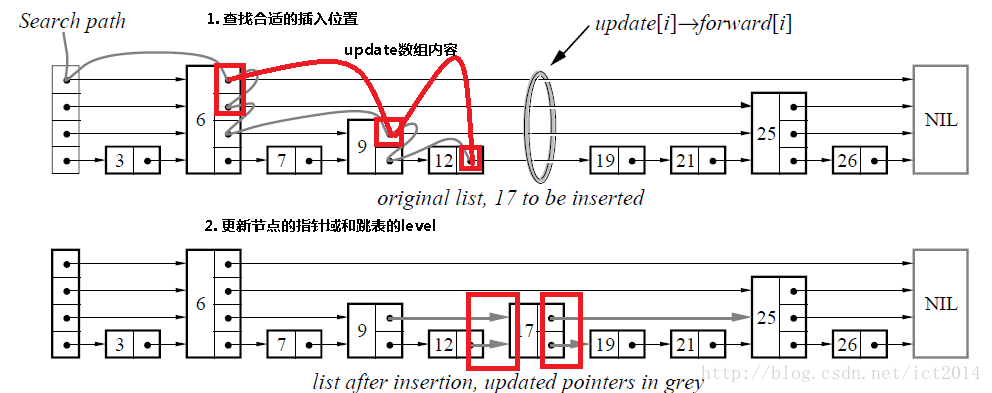
- 查找合适的插入位置,比如上图中要插入key为17的结点,就需要一路查找到12,由于12 < 17,而12的下一个结点19 > 17,因而满足条件
- 创建新结点,并且产生一个在1~MAX_LEVEL之间的随机level值作为该结点的level
- 调整指针指向
删除
移除结点的示意图如下:

移除结点其实很简单,就分以下3步:
- 查找到指定的结点,如果没找到则返回
- 调整指针指向
- 释放结点空间
伪代码
这里有一个HiWong实现的C++的伪代码,有兴趣的可以看下,github。
skiplist与平衡树、哈希表的比较
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key 的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
- 在做范围查找的时候,平衡树比skiplist 操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist 上进行范围查找就非常简单,只需要在找到小于目标值的节点之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p)
,具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含
1.33个指针,比平衡树更有优势。 - 查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1) ,性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。
Redis的skiplist结构
在Redis中,skiplist被用于实现暴露给外部的一个数据结构:sorted set。准确地说,sorted set底层不仅仅使用了skiplist,还使用了ziplist和dict。
sorted set的命令举例
下图来自tielei的博客
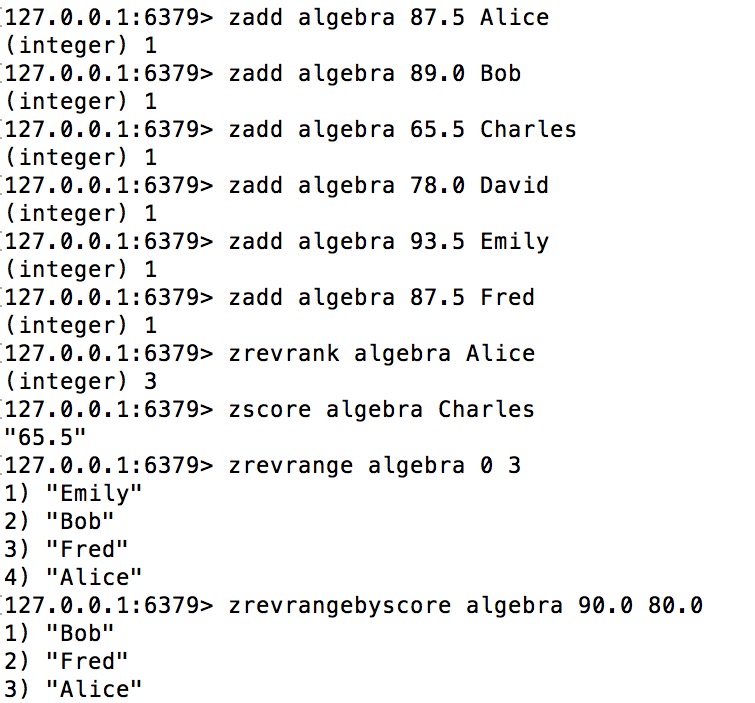 总结一下,sorted set中的每个元素主要表现出3个属性:
总结一下,sorted set中的每个元素主要表现出3个属性:
- 数据本身(在前面的例子中我们把名字存成了数据)。
- 每个数据对应一个分数(score)。
- 根据分数大小和数据本身的字典排序,每个数据会产生一个排名(rank)。可以按正序或倒序。
Redis中skiplist实现的特殊性
我们简单分析一下前面出现的几个查询命令:
- zrevrank 由数据查询它对应的排名,这在前面介绍的skiplist中并不支持。
- zscore 由数据查询它对应的分数,这也不是skiplist所支持的。
- zrevrange 根据一个排名范围,查询排名在这个范围内的数据。这在前面介绍的skiplist中也不支持。
- zrevrangebyscore 根据分数区间查询数据集合,是一个skiplist所支持的典型的范围查找(score相当于key)。
实际上,Redis中sorted set的实现是这样的:
- 当数据较少时,sorted set是由一个ziplist来实现的。
- 当数据多的时候,sorted set是由一个dict + 一个skiplist来实现的。简单来讲,dict用来查询数据到分数的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。
现在我们集中精力来看一下sorted set与skiplist的关系:
- zscore的查询,不是由skiplist来提供的,而是由那个dict来提供的。
- 为了支持排名(rank) ,Redis里对skiplist做了扩展,使得根据排名能够快速查到数据,或者根据分数查到数据(也是分数)之后,也同时很容易获得它的排名。而且,根据排名的查找,时间复杂度也为O(logn) ,跟利用score查没是区别,因为二者基本上是一样的功能。
- zrevrange的查询,是根据排名查数据,由扩展后的skiplist来提供。
- zrevrank是先在dict中由数据查到分数,再拿分数到skiplist中去查找,查到后也同时获得了排名。
前述的查询过程,也暗示了各个操作的时间复杂度:
- zscore 只用查询一个dict,所以时间复杂度为O(1)。
- zrevrank 要先查询dict获取对应的score,然后再根据score去skiplist中查找,时间复杂度是O(logn);而zrevrange, zrevrangebyscore的时间复杂度为O(log(n)+M),其中M是当前查询返回的元素个数。
- zrevrange 的时间复杂度为O(log(n)+M) ,其中M是当前查询返回的元素个数。注意其实zrevrange和zrange的性能没有差别,都会从header开始查询,时间复杂度为log (n),然后再根据查到的score去dict中依次获取对应的内容,这里的时间复杂度为O(M)
- zrevrangebyscore 的时间复杂度为O(log(n)+M) ,其中M是当前查询返回的元素个数。类似zrevrange,只不过前者用score,后者用rank而已,本质上是一样的。
总结起来,Redis中的skiplist跟前面介绍的经典的skiplist相比,有如下不同:
- 分数(score)允许重复,即skiplist的 key 允许重复。这在最开始介绍的经典skiplist中是不允许的。
- 在比较时,不仅比较分数score(相当于skiplist的 key ),还比较数据本身。在Redis的skiplist实现中,数据本身的内容唯一标识这份数据,而不是由key 来唯一标识。另外,当多个元素分数相同的时候,还需要根据数据内容来进字典排序。
- 第1层链表不是一个单向链表,而是一个双向链表。这是为了方便以倒序方式获取一个范围内的元素。
- 在skiplist中可以很方便地计算出每个元素的排名(rank)。
数据结构
跳表的数据结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
这段代码出自server.h,我们来简要分析一下:
- 开头定义了两个常量,ZSKIPLIST_MAXLEVEL和ZSKIPLIST_P,分别对应我们前面讲到的skiplist的两个参数:一个是MaxLevel,一个是p。
- zskiplistNode定义了skiplist的节点结构。
- obj字段存放的是节点数据,它的类型是一个string robj。本来一个string robj可能存放的不是sds,而是long型,但zadd命令在将数据插入到skiplist里面之前先进行了解码,所以这里的obj字段里存储的一定是一个sds。这样做的目的应该是为了方便在查找的时候对数据进行字典序的比较,而且,skiplist里的数据部分是数字的可能性也比较小。
- score字段是数据对应的分数。
- backward字段是指向链表前一个节点的指针(前向指针)。节点只有1个前向指针,所以只有第1层链表是一个双向链表。
- level[]存放指向各层链表后一个节点的指针(后向指针)。每层对应1个后向指针,用forward字段表示。另外,每个后向指针还对应了一个span 值,它表示当前的指针跨越了多少个节点。span用于计算元素排名(rank),这正是前面我们提到的Redis对于skiplist所做的一个扩展。需要注意的是,level[]是一个柔性数组(flexible array member),因此它占用的内存不在zskiplistNode结构里面,而需要插入节点的时候单独为它分配。也正因为如此,skiplist的每个节点所包含的指针数目才是不固定的,我们前面分析过的结论——skiplist每个节点包含的指针数目平均为1/(1-p)——才能有意义。
- zskiplist定义了真正的skiplist结构,它包含:
- 头指针header和尾指针tail。
- 链表长度length,即链表包含的节点总数。注意,新创建的skiplist包含一个空的头指针,这个头指针不包含在length计数中。
- level表示skiplist的总层数,即所有节点层数的最大值。
下面是一种可能的数据结构,图文来自zhangtielei:
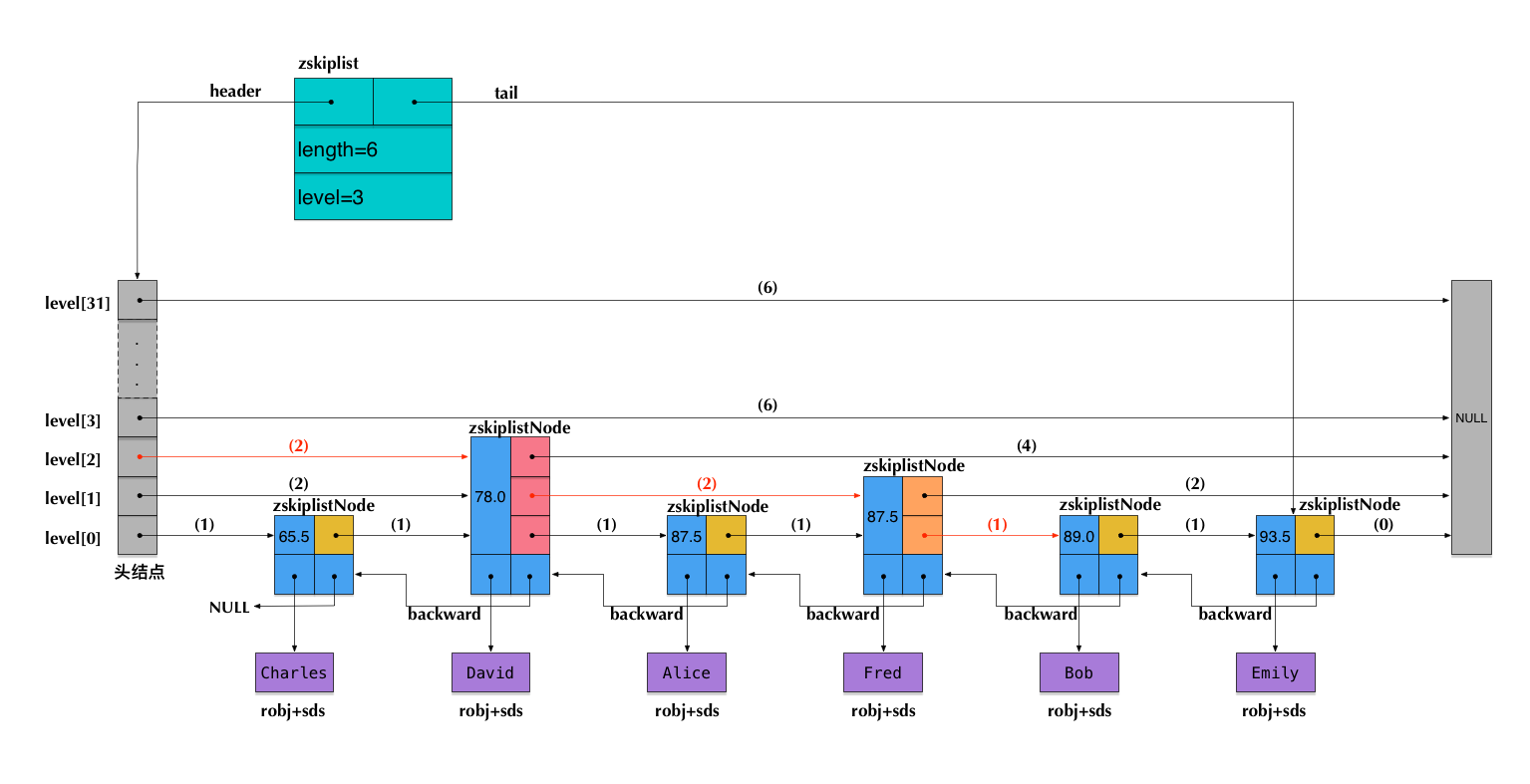 注意:图中前向指针上面括号中的数字,表示对应的span的值。即当前指针跨越了多少个节点,这个计数不包括指针的起点节点,但包括指针的终点节点。
注意:图中前向指针上面括号中的数字,表示对应的span的值。即当前指针跨越了多少个节点,这个计数不包括指针的起点节点,但包括指针的终点节点。
假设我们在这个skiplist中查找score=89.0的元素(即Bob的成绩数据),在查找路径中,我们会跨域图中标红的指针,这些指针上面的span值累加起来,就得到了Bob的排名(2+2+1)-1=4(减1是因为rank值以0起始)。需要注意这里算的是从小到大的排名,而如果要算从大到小的排名,只需要用skiplist长度减去查找路径上的span累加值,即6-(2+2+1)=1。
可见,在查找skiplist的过程中,通过累加span值的方式,我们就能很容易算出排名。相反,如果指定排名来查找数据(类似zrange和zrevrange那样),也可以不断累加span并时刻保持累加值不超过指定的排名,通过这种方式就能得到一条O(log n)的查找路径。
API和时间复杂度
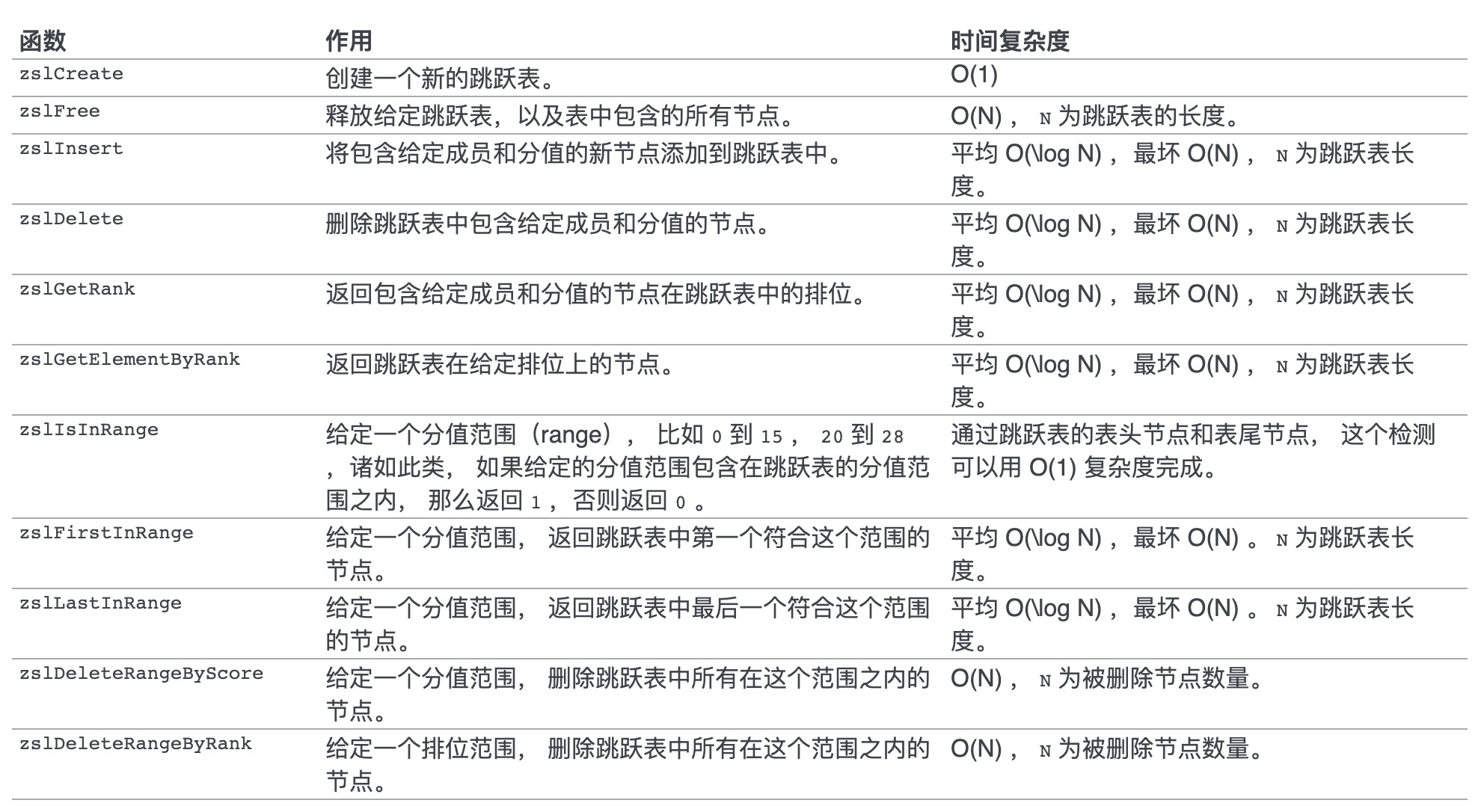 注:来源 Redis 设计与实现 。
注:来源 Redis 设计与实现 。
性能比较
作者在论文中给出了SkipList和AVL树以及其变种之间在查询、插入和删除操作上的时间开销对比:
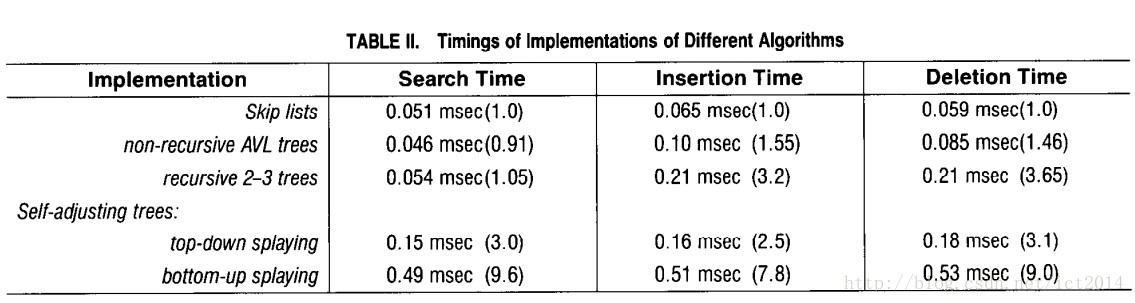
Redis为什么用skiplist而不用平衡树?Redis的作者 @antirez 从内存占用、对范围查找的支持和实现难易程度做了解释。原文:
There are a few reasons:
1) They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code. ```
References
- http://redisbook.com/
- https://blog.csdn.net/ict2014/article/details/17394259
- http://zhangtielei.com/posts/blog-redis-skiplist.html
本文首次发布于 LiuShuo’s Blog, 转载请保留原文链接.