ziplist是一个经过特殊编码的List,但它
并不是链表或双向链表,而是一块连续的内存空间来存储,它的设计目标就是为了提高存储效率,Redis中的hash和sorted set两种数据结构底层都有它的存在,它是如何保存hash的field和value的以及它是如何保存zset的member和score的?本文对其进行一定的分析。
什么是ziplist
Redis官方对于ziplist的定义是(出自ziplist.c的文件头部注释):
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time.
即,ziplist是一个经过特殊编码的 双向链表
,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。
它能以 O(1) 的时间复杂度在表的两端提供 push 和pop 操作。
实际上,ziplist充分体现了Redis
对于「存储效率」的追求。一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的 内存碎片
,而且地址指针也会占用额外的内存。而ziplist
却是将表中每一项存放在前后 连续的地址空间 内,一个ziplist整体占用一大块内存。 它是一个表(list),但其实不是一个链表(linked list) 。
ziplist的数据结构定义
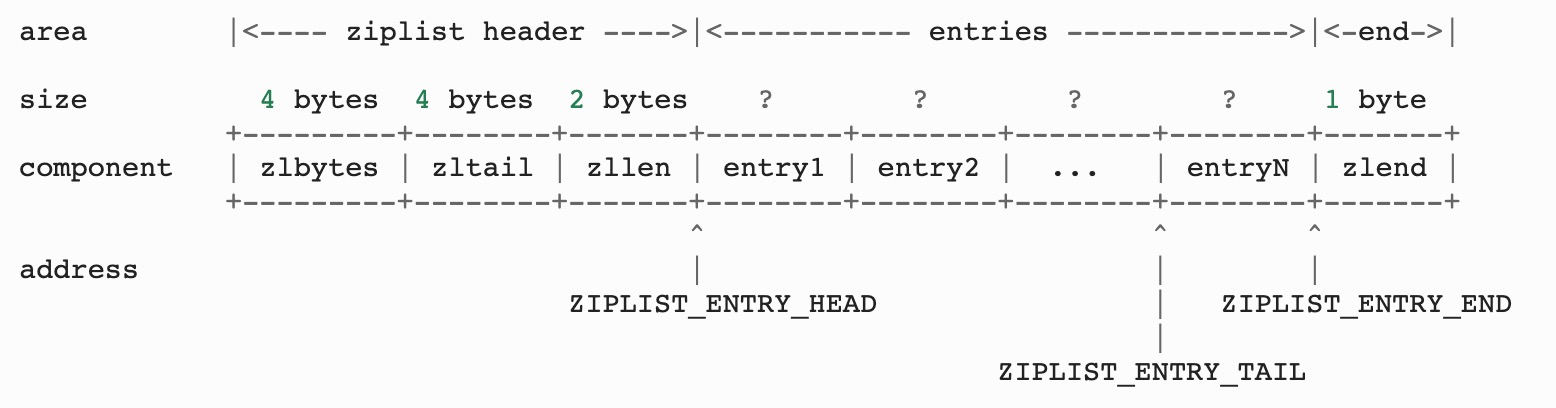
- zlbytes: 32bit,表示ziplist占用的字节总数(也包括zlbytes本身占用的4个字节)。
- zltail: 32bit,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。zltail的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist ),从而可以在ziplist 尾端 快速地执行push或pop操作。
- zllen: 16bit, 表示ziplist中数据项(entry)的个数。zllen字段因为 只有16bit,所以可以表达的最大值为2^16-1。这里需要特别注意的是,如果ziplist 中数据项个数超过了16bit能表达的最大值,ziplist仍然可以来表示。那怎么表示呢?这里做了这样的规定:如果zllen小于等于2^16-2(也就是不等于2^16-1),那么zllen就表示ziplist中数据项的个数;否则,也就是zllen等于16bit全为1的情况,那么zllen就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。
- entry: 表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构,这个稍后再解释。
- zlend: ziplist最后1个字节,是一个结束标记,值固定等于255。
上面的定义中还值得注意的一点是:zlbytes, zltail, zllen既然占据多个字节,那么在存储的时候就有大端(big endian)和小端(little endian)的区别。ziplist采取的是小端模式来存储,这一点和ProtoBuffer是一样的。在解析多个字节序列时需要特别注意调换顺序。
为什么最后一个值固定为255呢?
这是因为:255已经定义为ziplist结束标记zlend的值了。在ziplist的很多操作的实现中,都会根据数据项的第1个字节是不是255来判断当前是不是到达ziplist 的结尾了,因此一个正常的数据的第1个字节(也就是prev_entry_len的第1个字节)是不能够取255这个值的,否则就冲突了。
ziplist entry

pre_entry_length
根据编码方式的不同, pre_entry_length 域可能占用 1 字节或者 5 字节:
- 1 字节:如果前一节点的长度小于 254 字节,便使用一个字节保存它的值。
- 5 字节:如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然后用接下来的 4 个字节保存实际长度。
encoding 和 length
encoding 和 length 两部分一起决定了 content 部分所保存的数据的类型(以及长度)。
其中, encoding 域的长度为两个 bit , 它的值可以是 00 、 01 、 10 和 11 :
- 00 、 01 和 10 表示 content 部分保存着字符数组。
- 11 表示 content 部分保存着整数。

content
content 部分保存着节点的内容,类型和长度由 encoding 和 length 决定。 先分析前两个bit的值,对应到具体的数据类型,然后再根据上表分析后面的内容的真实长度。
对于hash来说,如果一个field的值全是数字,但是由超过了int64的最大值,这个时候该怎么存储呢?是截断为多个int存储还是退化为字符串存储?这个要注意Redis 本身有一个配置,如果value的长度超过了预设的大小,不管是不是纯数字,都不会再用ziplist存储了而是用skiplist。下文会继续讲这个问题。
例子
这个例子来自zhangtielei:
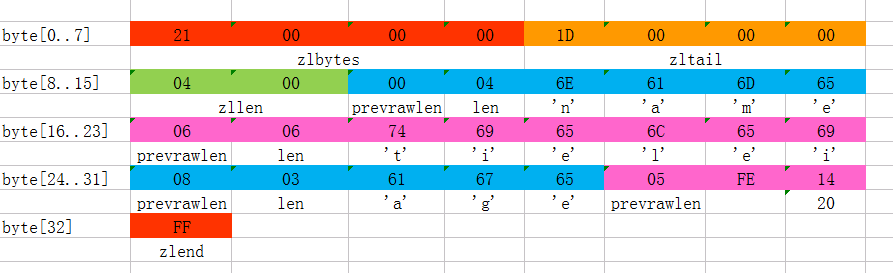
上图是一份真实的ziplist数据。我们逐项解读一下:
- 这个ziplist一共包含33个字节。字节编号从byte[0]到byte[32]。图中每个字节的值使用16进制表示。
- 头4个字节(0x21000000)是按小端(little endian)模式存储的zlbytes字段。因此,这里zlbytes的值应该解析成0x00000021,用十进制表示正好就是33。
- 接下来4个字节(byte[4..7])是
,用小端存储模式来解释,它的值是0x0000001D(值为29),表示最后一个数据项在byte[29]的位置(那个数据项为0x05FE14)。 - 再接下来2个字节(byte[8..9]),值为0x0004,表示这个ziplist里一共存有4项数据。
- 接下来6个字节(byte[10..15])是第1个数据项。其中,prev_entry_len=0,因为它前面没有数据项;len=4,即0x04,相当于前面定义的9种情况中的第1种,表示后面4 个字节按字符串存储数据,数据的值为”name”。
- 接下来8个字节(byte[16..23])是第2个数据项,与前面数据项存储格式类似,存储1个字符串”tielei”。
- 接下来5个字节(byte[24..28])是第3个数据项,与前面数据项存储格式类似,存储1个字符串”age”。
- 接下来3个字节(byte[29..31])是最后一个数据项,它的格式与前面的数据项存储格式不太一样。其中,第1个字节prev_entry_len=5,表示前一个数据项占用5个字节;第2个字节=0xFE ,相当于前面定义的9种情况中的第8种,所以后面还有1个字节用来表示真正的数据,并且以整数表示。它的值是20(0x14)。
- 最后1个字节(byte[32])表示zlend,是固定的值255(0xFF)。
总结一下,这个ziplist里存了4个数据项,分别为:
- 字符串: “name”
- 字符串: “tielei”
- 字符串: “age”
- 整数: 20
注意:这个ziplist是通过两个 hset 命令创建出来的:
1
2
hset myinfo name tielei
hset myinfo age 20
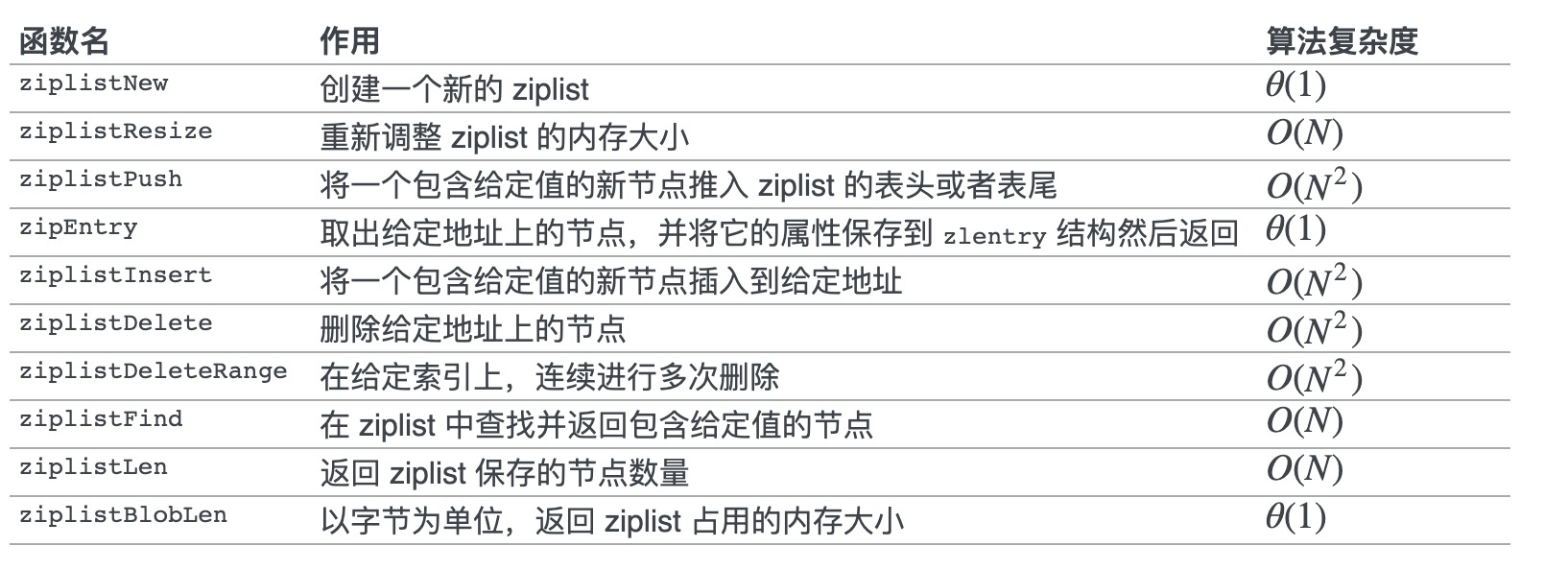
API和时间复杂度
hash与ziplist的关系
hash是Redis中可以用来存储一个对象结构的比较理想的数据类型。一个对象的各个属性,正好对应一个hash结构的各个field。
我们在网上很容易找到这样一些技术文章,它们会说存储一个对象,使用hash比string要节省内存。实际上这么说是有前提的, 具体取决于对象怎么来存储。如果你把对象的多个属性存储到多个key上(各个属性值存成string),当然占的内存要多。 但如果你采用一些序列化方法,比如Protocol Buffers,或者Apache Thrift,先把对象序列化为字节数组,然后再存入到Redis的string中, 那么跟hash相比,哪一种更省内存,就不一定了。
当然,hash比序列化后再存入string的方式,在支持的操作命令上是有优势的:它既支持多个field同时存取(hmset/hmget),
也支持按照某个特定的field单独存取(hset/hget)。
实际上,hash随着数据的增大,其底层数据结构的实现是会发生变化的,当然存储效率也就不同。
- 在field比较少,各个value值也比较小的时候,hash采用ziplist来实现;
- 而随着field增多和value值增大,hash可能会变成dict来实现。当hash底层变成dict来实现的时候,它的存储效率就没法跟那些序列化方式相比了。
当我们为某个key第一次执行 hset key field value 命令的时候,Redis会创建一个hash结构,这个新创建的hash底层就是一个ziplist。
当随着数据的插入,hash底层的这个ziplist就可能会转成dict。那么到底插入多少才会转呢?
1
2
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
这个配置的意思是说,在如下两个条件之一满足的时候,ziplist会转成dict:
- 当hash中的数据项(即field-value对)的数目超过512的时候,也就是ziplist数据项超过1024的时候(请参考t_hash.c中的hashTypeSet函数)。
- 当hash中插入的任意一个value的长度超过了64的时候(请参考t_hash.c中的hashTypeTryConversion函数)。
Redis的hash之所以这样设计,是因为当ziplist变得很大的时候,它有如下几个缺点:
- 每次插入或修改引发的realloc操作会有更大的概率造成内存拷贝,从而降低性能。
- 一旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更大的一块数据,类似COW的复制机制。
- 当ziplist数据项过多的时候,在它上面查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
sorted set和ziplist的关系
Redis中的sorted set,是在skiplist、dict和ziplist基础上构建起来的:
- 当数据较少时,sorted set是由一个ziplist来实现的。
- 当数据多的时候,sorted set是由一个叫zset的数据结构来实现的,这个zset包含一个dict + 一个skiplist。dict用来查询数据(member)到分数(score) 的对应关系,而skiplist用来根据分数或者(分数or排名)范围查询数据。这样skiplist中只需要通过指针来获取对应分数的键member,而不用管键到底占了多大空间,把它交给dict去存储。
说回用ziplist保存sorted set数据的case:
ziplist就是由很多数据项组成的一大块 连续内存 。由于sorted set的每一项元素都由数据和score组成,因此,当使用zadd命令插入一个 (数据, score) 对的时候,底层在相应的ziplist上就插入两个数据项:数据在前,score紧跟在后,如上面的例子中的图例。
ziplist的主要优点是节省内存,但它上面的查找操作只能按顺序查找(可以正序也可以倒序)。因此,sorted set的各个查询操作,就是在ziplist上从前向后(或从后向前)一步步查找,每一步前进两个数据项,跨越一个 (数据, score) 对。
随着数据的插入,sorted set底层的这个ziplist就可能会转成zset的实现(转换过程详见t_zset.c的zsetConvert)。那么到底插入多少才会转呢?
我们可以通过命令获取Redis实例关于ziplist的配置:
1
2
3
4
5
6
7
8
9
10
11
127.0.0.1:6379> config get '*ziplist*'
1) "hash-max-ziplist-entries"
2) "512"
3) "hash-max-ziplist-value"
4) "64"
5) "list-max-ziplist-size"
6) "-2"
7) "zset-max-ziplist-entries"
8) "128"
9) "zset-max-ziplist-value"
10) "64"
我们主要关注后两个关于zset结构的配置,最大entry个数为128个,以及最大的entry中的value长度为64,一旦超过了这两个限制中的一个,那么Redis将使用 skiplist 来实现zset结构。
zset结构的代码定义如下:
1
2
3
4
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
光说不练,验证一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
127.0.0.1:6379> get zset1
(nil)
127.0.0.1:6379> zadd zset1 1.0 12345
(integer) 1
127.0.0.1:6379> object encoding zset1
"ziplist" -- 默认ziplist实现sorted set
127.0.0.1:6379> zadd zset1 1.0 12345012345678901234567890123456789012345678901234567890123456789
(integer) 1
127.0.0.1:6379> object encoding zset1
"skiplist" -- member长度超过了最大值则自动转化为skiplist,不再使用ziplist
127.0.0.1:6379> zadd zset1 2.0 23456
(integer) 1
127.0.0.1:6379> object encoding zset1
"skiplist"
127.0.0.1:6379> zrange zset1 0 -1
1) "12345"
2) "12345012345678901234567890123456789012345678901234567890123456789"
3) "23456"
127.0.0.1:6379> zrem zset1 12345012345678901234567890123456789012345678901234567890123456789
(integer) 1
127.0.0.1:6379> object encoding zset1
"skiplist" -- 不会回退成ziplist
可以发现一旦value超过了64字节则会变成skiplist结构,并且不会再回退会为ziplist结构。
References
- http://zhangtielei.com/posts/blog-redis-ziplist.html
- https://redisbook.readthedocs.io/en/latest/compress-datastruct/ziplist.html
本文首次发布于 LiuShuo’s Blog, 转载请保留原文链接.