先抛出一个问题,如果客户端通过TCP连接了服务器的某个端口后,不停的调用send()发送数据,但是服务器就是不recv(),会发生什么?
问题
这个问题比较开放,它考察了关于TCP缓冲区、滑动窗口等多个知识点,想一下子就想清楚也不是很容,让我们来一步一步来揭开这个问题。
首先需要来一点基础知识,这里借鉴了这篇写的很通透的文章 ,感谢作者的付出。
基础知识
用户进程和操作系统的关系
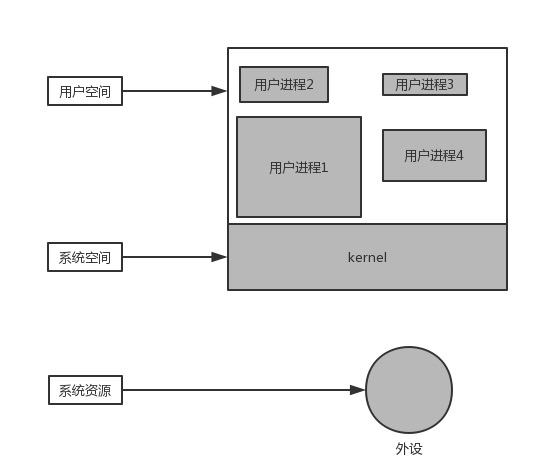 这是一个计算机系统运行时的简化模型,我们把所有运行在操作系统上的进程成为用户进程,它们都运行在用户空间(可以看到用户空间有很多进程)。把操作系统运行的空间成为系统空间。
这是一个计算机系统运行时的简化模型,我们把所有运行在操作系统上的进程成为用户进程,它们都运行在用户空间(可以看到用户空间有很多进程)。把操作系统运行的空间成为系统空间。
为什么将进程分为用户进程和系统进程,首先你一定听说过内核态和用户态(Kernel Mode和User Mode),在内核态可以访问系统资源,比如:
- 处理器CPU:控制着一个程序的执行。
- 输出输出IO:Linux有句话叫“一切都是流”,也就是所有输入输出设备的数据,包括硬盘,内存,终端都可以像流一样操作。
- 进程管理:类似对进程的创建,休眠,唤醒,释放之类的调度。比如Linux下的fork和Windows下的CreateProcess()函数。
- 内存: 包括内存的申请,释放等管理操作。
- 设备:这个就是常常说的外设了,比如鼠标,键盘。
- 计时器:计算机能计时是因为晶体振荡器产生的电磁脉冲。那么所有的定时任务都是以它为基础的。
- 进程间通信(IPC),进程之间是不能够互相访问内存的,所以进程与进程之间的交互需要通信,而通信也是一种资源。
- 网络通信:网络通信可以看做是进程见通信的特殊形式。
而上面所说的这些系统资源,在用户进程中是无法被直接访问的,只能通过操作系统来访问,所以也把操作系统提供的这些功能成为:“系统调用”。
比如下图,展示一个用户通过shell控制计算机所经过的数据流向:文件读写和终端控制,都是通过内核进行的。
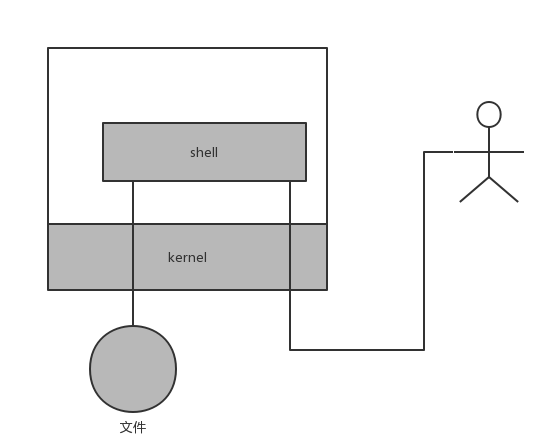
提供这些限制的基础就是CPU提供的内核态和用户态。比如intel x86 CPU有四种不同的执行级别0-3,Linux只使用了其中的0级和3级分别来表示内核态和用户态。
在用户态,不仅仅是系统资源了,就是别的进程的内存对于你来说,都是“透明的”(并不是没办法访问,否则游戏作弊器怎么实现?)
用户进程缓冲区
前面提到,用户进程通过系统调用访问系统资源的时候,需要切换到内核态,而这对应一些特殊的堆栈和内存环境,必须在系统调用前建立好。而在系统调用结束后,CPU 会从核心模式切回到用户模式,而堆栈又必须恢复成用户进程的上下文。而这种切换就会有大量的耗时。
你看一些程序在读取文件时,会先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer。(用较小的次数填满buffer)。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。
所以说:用户缓冲区的目的是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。
内核缓冲区
除了在进程中设计缓冲区,内核也有自己的缓冲区。
当一个用户进程要从磁盘读取数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程缓冲区中。
但若是内核缓冲区中没有数据,内核会把对数据块的请求,加入到请求队列,然后把进程挂起,为其它进程提供服务。
等到数据已经读取到内核缓冲区时,把内核缓冲区中的数据读取到用户进程中,才会通知进程,当然不同的io模型,在调度和使用内核缓冲区的方式上有所不同,下一小结介绍。
你可以认为,read是把数据从内核缓冲区复制到进程缓冲区。write是把进程缓冲区复制到内核缓冲区。
当然,write并不一定导致内核的写动作,比如os可能会把内核缓冲区的数据积累到一定量后,再一次写入。这也就是为什么断电有时会导致数据丢失。
所以说内核缓冲区,是为了在OS级别,提高磁盘IO效率,优化磁盘写操作。
流程
在《Unix网络编程》中的五种io模型,也提到过进程缓冲区和内核缓冲区。
因为这个并不是此篇博客的重点,所以这里只对比阻塞模型和非阻塞。
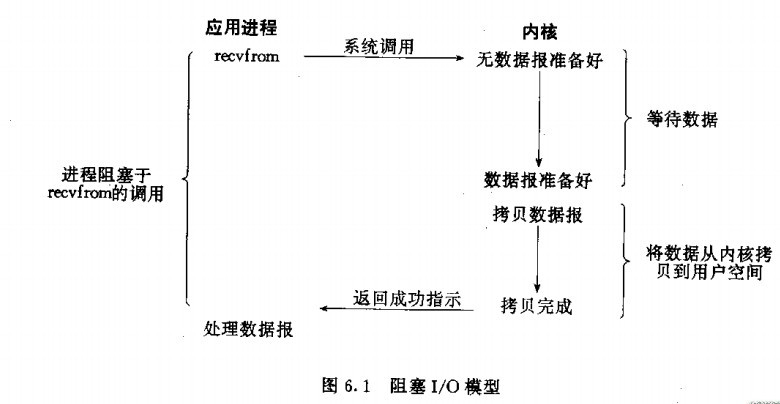
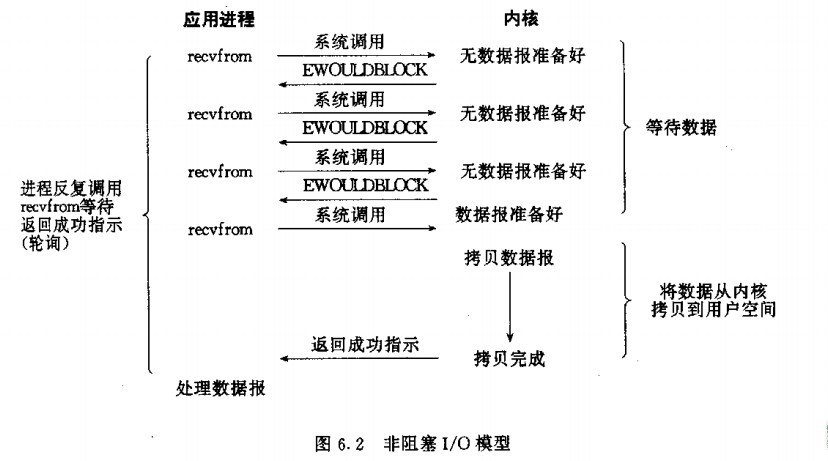
回到问题
有了上面的基础知识我们知道:
- 当某个应用进程调用套接字的write方法时,会先将数据写入该应用进程的缓冲区,此后内核会从该应用进程的缓冲区复制所有数据到要写的套接字的发送缓冲区。
- 如果该套接字的发送缓冲区容不下该应用进程的所有数据(或是应用进程的缓冲区大于套接字的发送缓冲区,或是套接字的发送缓冲区中已有其他数据), 该应用进程则无法继续写入自身的缓冲区,此时将会被阻塞住。内核将不从write系统调用返回,直到应用进程缓冲区中的所有数据都复制到套接字发送缓冲区。
- 如果调用TCP套接字的write方法并成功返回时,仅仅能代表我们可以重新使用原来的应用进程缓冲区,并不表明对端的TCP或应用进程已接收到数据,数据可能还在TCP的发送缓冲区中。
下面是一个网络通信的模型图,很清晰的画出了这个问题的一些核心的点:
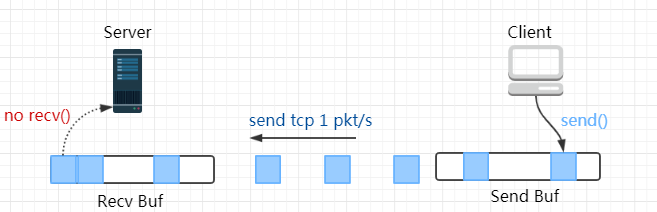
一个Socket的两端,都会有send()和recv()两个方法,如Client发送数据到Server,那么就是客户端进程调用send()发送数据,而send()的作用是将数据拷贝进入Socket 的内核发送缓冲区之中,然后send()便会在上层返回。
也就是说send()方法返回之时,数据不一定会发送到对端即服务器上去(和write写文件有点类似),send()仅仅是把应用层buffer的数据拷贝进Socket的内核发送buffer中,发送是TCP的事情,和send()其实没有太大关系。
所以有了上面的知识,我们知道大概的会发生如下的流程:
- Phase 1 Server 端的 socket 接收缓冲区未满,所以尽管 Server 不会 recv(),但依然能对 Client 发出的报文回复 ACK;
注:接收缓冲区把数据缓存入内核,等待recv()读取,recv()所做的工作就是把内核缓冲区中的数据拷贝到应用层用户空间的buffer里面并返回。 若应用进程一直没有调用recv()进行读取的话,此数据会一直缓存在相应Socket的接收缓冲区内。
- Phase 2 Server 端的 socket 接收缓冲区被填满了,向 Client 端通告零窗口(Zero Window)。Client 端待发送的数据开始累积在 socket 的发送缓冲区;
注:这个便是滑动窗口的实现,保证TCP套接口接收缓冲区不会溢出,从而保证了TCP是可靠传输。因为对方不允许发出超过所通告窗口大小的数据。 这就是TCP的流量控制,如果对方无视窗口大小而发出了超过窗口大小的数据,则接收方TCP将丢弃它。
- Phase 3 Client 端的 socket 的发送缓冲区满了,用户进程阻塞在 send() 上。
References
本文首次发布于 LiuShuo’s Blog, 转载请保留原文链接.